Twine Case Study
1.0 Introduction
Twine is a scalable and open-source RaaS (Real-time as a Service), designed to reliably abstract away the complexity of real-time communication for modern web applications.
Twine automates the deployment of real-time architecture by utilizing developer-owned AWS cloud services. This architecture provides a load-tested pub/sub mechanism that developers access through a secure API, and default connection state recovery in the case of client-service disruption. Additionally, it persists all published data as a backup, while providing developers with complete control over their Twine service and all of the data that travels through it.
The following sections explore the details of real-time communication, share insights from our journey in building Twine, discuss the project's challenges, and present the solutions we implemented to overcome those challenges. Finally, we outline Twine's roadmap going forward.
2.0 Real-time Communication
2.1.0 What is Real-time?
Real-time communication is a way of describing an exchange of information over a network at a speed that humans perceive as instantaneous. In reality, there is no such thing as instantaneous data transmission: there is always latency. This is due to several variables, ranging from the TCP handshake to head-of-line blocking, and even to the physical network layer of cables and cords.
Response times of up to 100 milliseconds are often categorized as real-time [1]. This benchmark is based on the 250 milliseconds the average human requires to register and process a visual event [1]. In the context of real-time communication, this provides a human-centered benchmark for what can be perceived as instantaneous.
2.2.0 Real-time in the real world
We engage in real-time communication constantly. It facilitates text messaging with our friends and family. It enables video calls for work or catch-ups on Zoom. It allows co-workers to share thoughts and coordinate schedules over Slack. Stock market traders rely on real-time feeds for timely market updates. It is even used by emergency response services to dispatch help quickly in critical situations. Ultimately, real-time communication underpins all these interactions, infusing our daily exchanges with a sense of speed and connectivity.
Real-time communication can be broadly categorized into two domains: "hard" and "soft."
“Hard” real-time communication is distinguished by its essential role in scenarios where immediate responses are paramount. For instance, emergency services like 911 rely on split-second decision-making to dispatch help swiftly. Similarly, real-time communication is vital for safe flight operations in aerospace and aviation. Any delay in communication could have severe consequences.
In contrast, “soft” real-time communication does not carry the same responsibility as "hard" real-time communication. It is also the category most commonly encountered in web applications that use real-time communication. Soft real-time applications include messaging, video conferencing, and online gaming, where slight delays do not have life-or-death implications but are crucial for effective collaboration and user experience. This is the real-time domain that Twine facilitates.
2.3.0 Implementing real-time communication
Hypertext Transfer Protocol (HTTP) plays a pivotal role in real-time communication. Developed for the World Wide Web, HTTP facilitates the exchange of information between clients, such as web browsers, and servers, such as a remote machine that hosts web application logic. The essence of HTTP lies in its request-response cycle, where clients send requests for specific resources, and servers respond by delivering the requested data.
Let's take a look at some of the ways that modern real-time communication has been achieved.
2.3.1 Polling
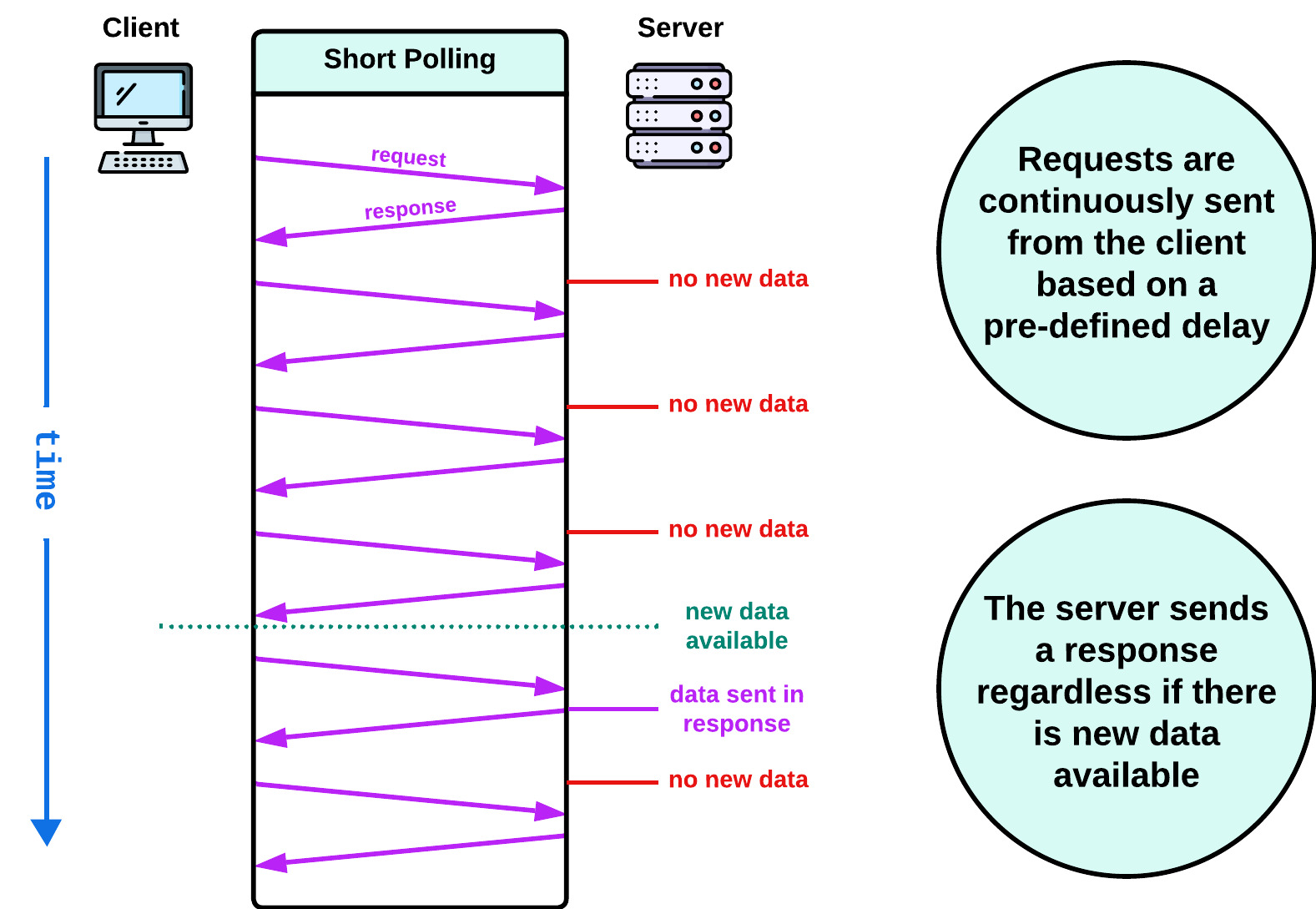
Polling is a technique for actively seeking updates or fresh information from a server. It involves the client, typically a web browser, sending HTTP requests at regular intervals that check for server updates. In response, the server provides the client with the most up-to-date information available.
In short polling, the client consistently checks the server for updates and receives immediate responses. This method, while quick, increases network traffic due to frequent requests.
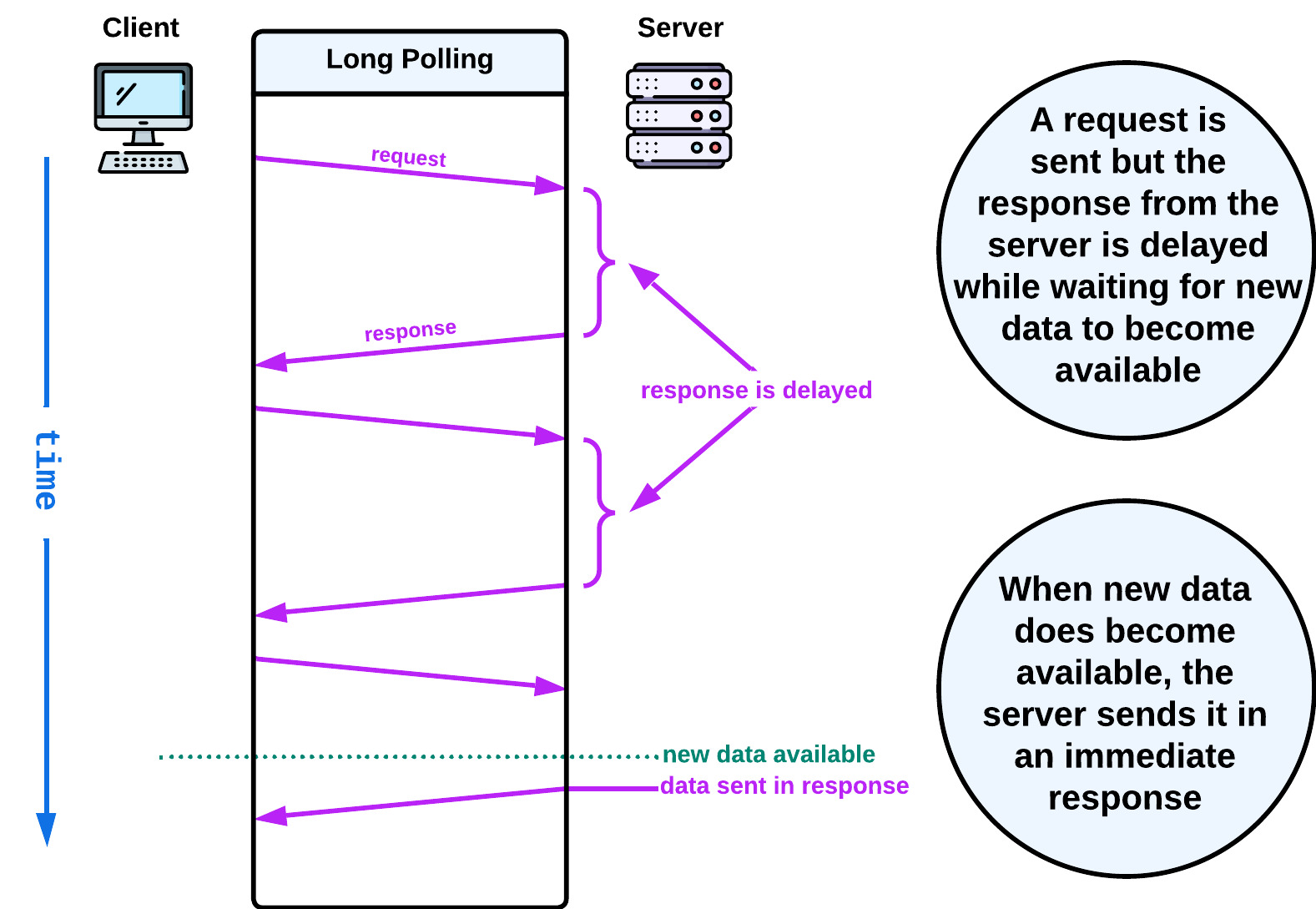
Long polling addresses this inefficiency by delaying the server's response to a client's request until the server has new data to send or the request times out; which cuts down on the number of request-response cycles.
As a method of real-time communication, polling has its drawbacks:
- It can be resource-intensive, demanding frequent request-response cycles that add latency.
- It often sends requests when no updates are available, leading to unnecessary data transfer.
As a result, more modern techniques like server-sent events and WebSockets have gained prominence in achieving real-time communication.
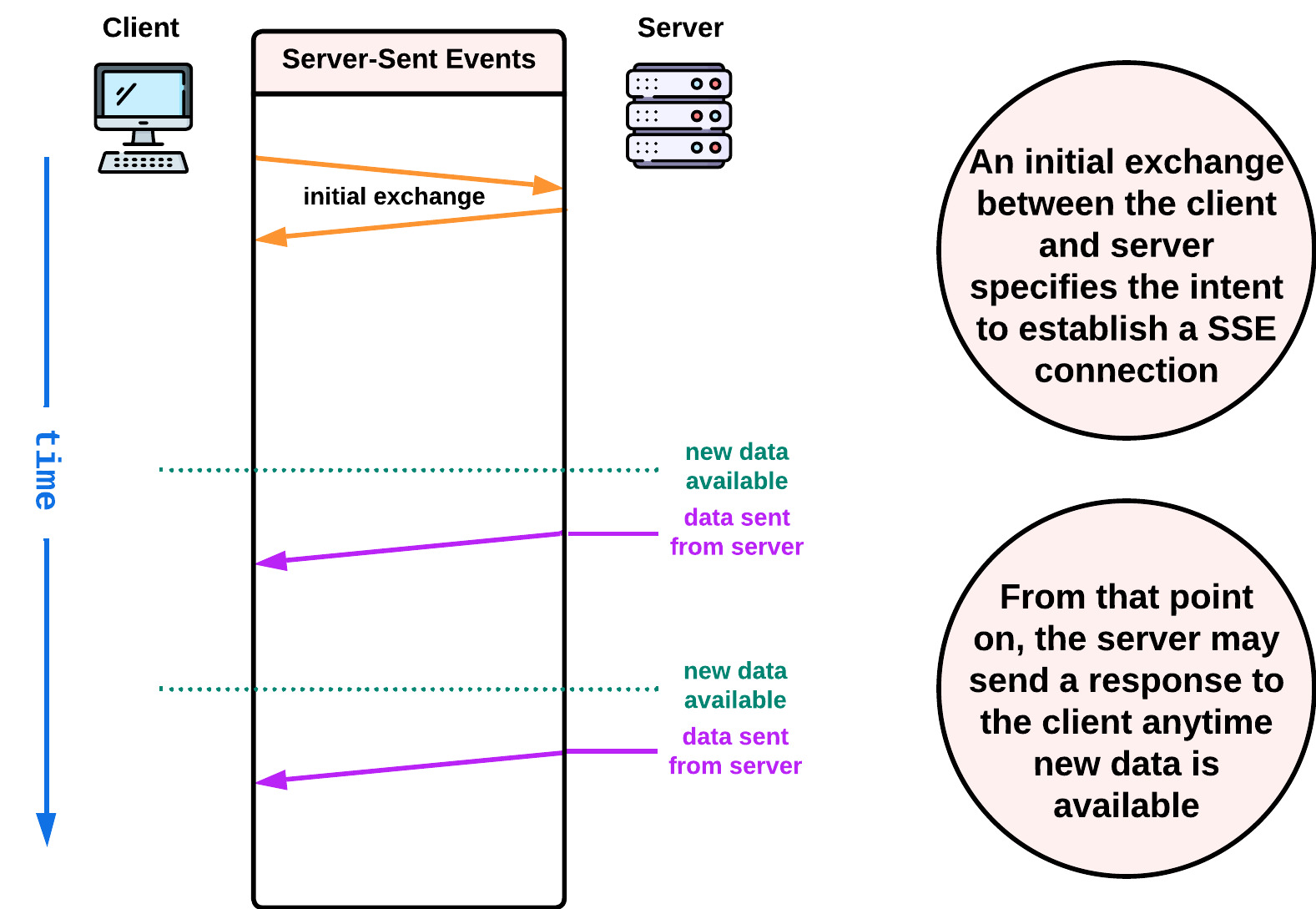
2.3.2 Server-Sent Events (SSE)
Server-sent events are a technology designed to facilitate real-time communication between a server and a client over a single HTTP connection [3]. Unlike traditional polling methods, where the client repeatedly requests information from the server, SSE allows the server to proactively push updates to the client as soon as new data becomes available.
SSE are less resource intensive than HTTP polling yet only support unidirectional communication from server to client, which limits their usefulness in applications that require bidirectional communication. Additionally, their browser support is less robust than that of WebSockets.
2.3.3 Websockets
WebSocket is a communication protocol that establishes a long-lived and bidirectional connection between a client and a server. WebSockets are established with an initial HTTP request-response exchange, where the client sends an upgrade request to the server, signifying the transition to the WebSocket protocol. If the server supports WebSockets, the connection is upgraded from HTTP to WebSocket [4].
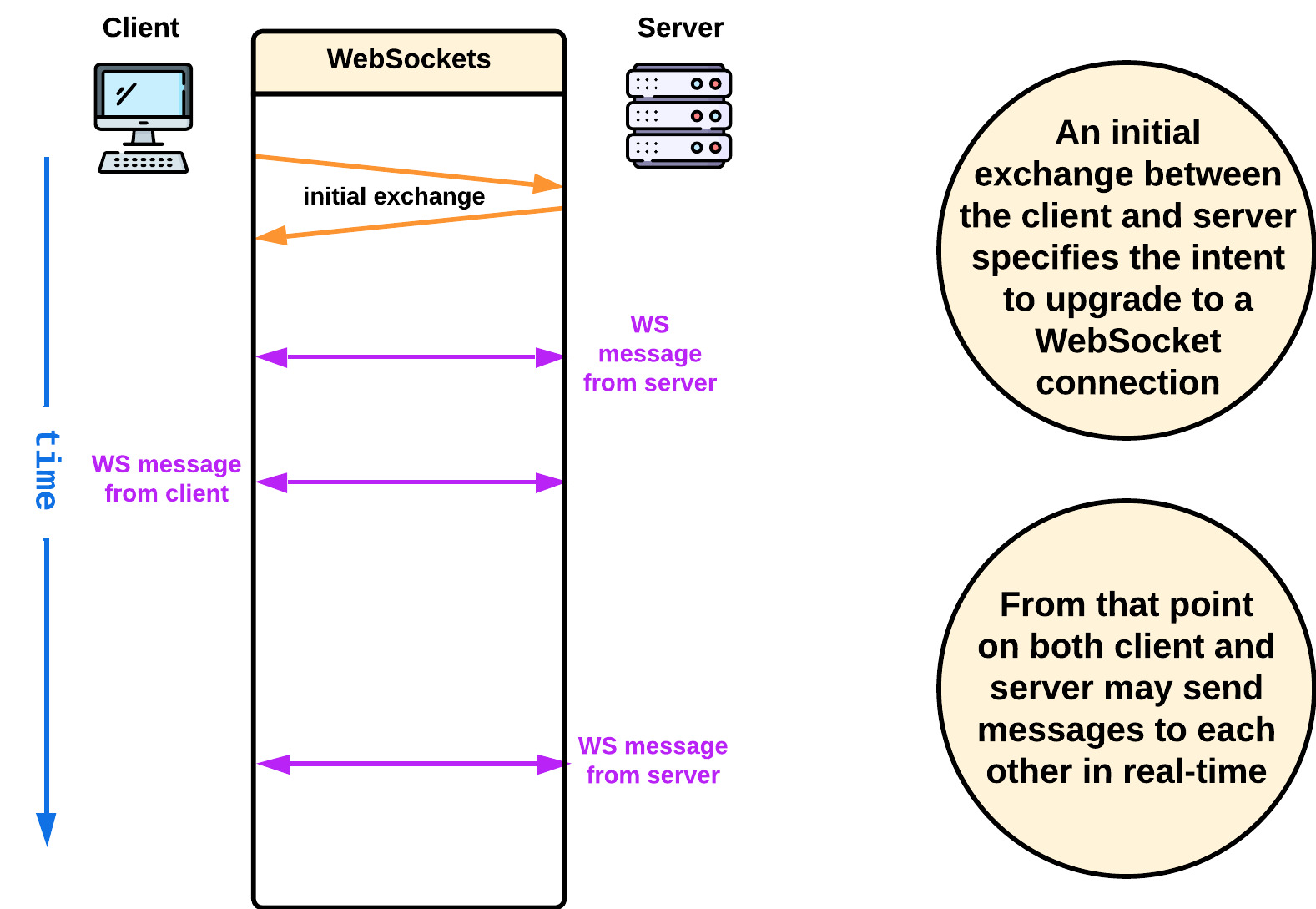
Although WebSocket connections require HTTP to establish an initial connection, HTTP and WebSockets are two separate communication protocols and have distinct characteristics [5]:
- Request-Response vs Bidirectional - HTTP works in a request-response pattern where a client sends a request and the server responds accordingly. In contrast, Websockets maintain a single connection between the client and server over which data is transmitted in either direction.
- Short-lived vs Long-lived - The HTTP request-response cycle is short-lived; once an HTTP request is sent to the server and a response is received, the connection is closed. WebSockets are long-lived and maintain a constant, open channel for data transmission between the client and server.
- Slow vs Fast - HTTP requires initiating a new request-response cycle for each interaction, which increases latency, especially for small, frequent updates. WebSockets, on the other hand, offer faster communication. After the initial HTTP connection required to establish the WebSocket connection, it remains open, allowing for continuous data exchange.
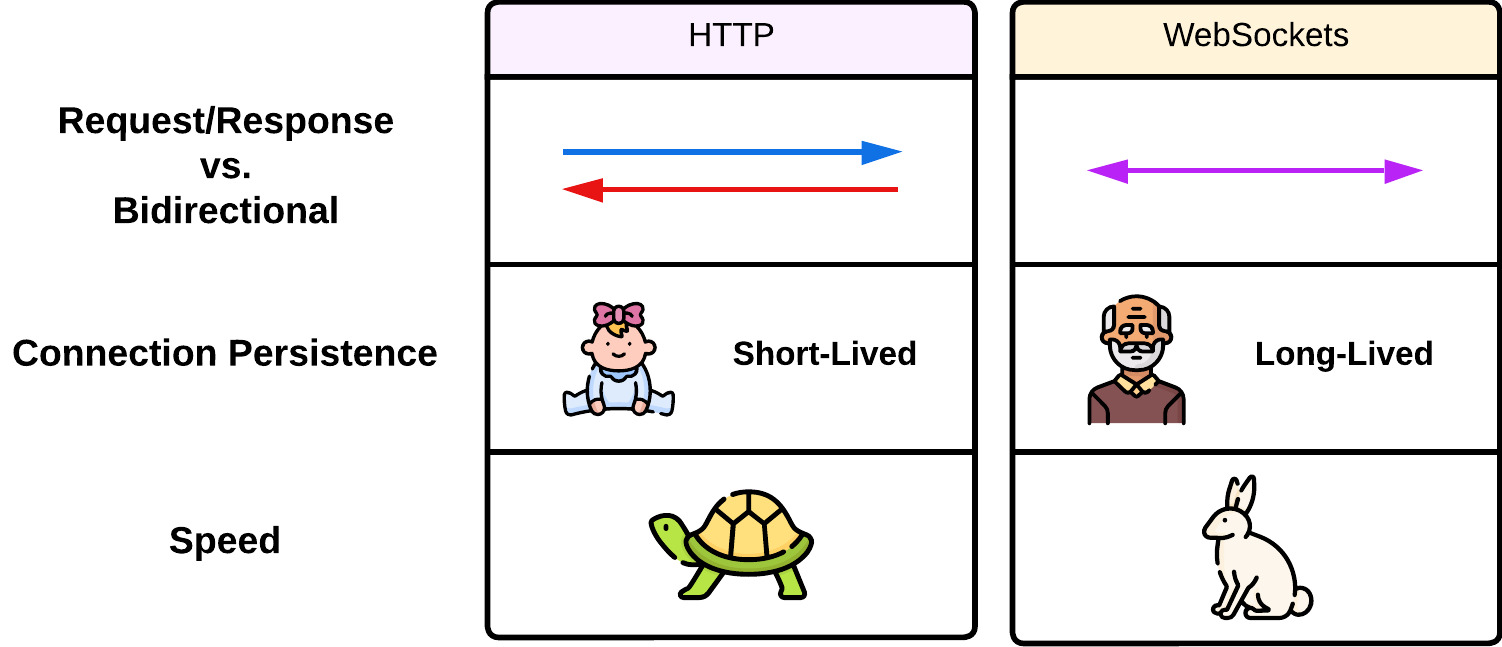
We can see from this comparison that WebSockets have advantages as a method for implementing real-time communication:
- Once a WebSocket connection is established, data can be transmitted over it without additional request-response cycles which reduces latency.
- The ability of data to flow in either direction (from client to server and vice versa) over a single WebSocket connection makes them a great choice for applications that require this bidirectional communication.
It is these advantages as well as the wide adoption of WebSockets by modern web applications such as GitHub and Slack that led us to use them in our implementation of Twine [37].
However, it is also important to note that WebSockets have disadvantages when compared to traditional HTTP, polling, and Server-sent events that make them not the best choice for all use cases:
- Since WebSocket connections are long-lived, the server is now tasked with maintaining them which requires ongoing server resources such as CPU and memory.
- WebSockets are particularly sensitive to network disruptions due to their long-lived nature.
- WebSocket is a distinct protocol from HTTP and many existing infrastructures are built, configured, and maintained to accommodate HTTP traffic without considering the requirements of WebSockets.
- Although now supported by all major browsers, certain environments such as corporate networks and proxy servers may block WebSocket connections.
3.0 The Challenges of Using Websockets in Real-Time Communication
As discussed, WebSockets are optimal for many real-time use cases but also have disadvantages. The Twine team set out to design and build a reliable real-time drop-in service that addresses two of these core challenges:
- Recovering lost data in the event of a dropped WebSocket connection
- Making Twine's real-time service scalable, which is difficult due to the ongoing server resources required to maintain a growing number of long-lived WebSocket connections
3.1.0 Difficulty of Scaling WebSockets
We labeled Twine as a scalable, open-source Real-time as a Service that can be dropped into an existing web application. But what exactly does scalability entail, and what is a drop-in service? In this section, we explain what scaling involves when dealing with WebSockets. Additionally, we clarify the notion of being a drop-in service and explain our decision to establish a dedicated infrastructure. This includes unpacking the advantages of this decision and outlining the challenges it brought to the forefront.
3.1.1 Scaling
Scalability refers to a software system's capability to manage a growing workload without a significant decline in performance or responsiveness.
“Scalable systems are designed to adapt to varying workloads, ensuring the stability of the overall system.” [12]
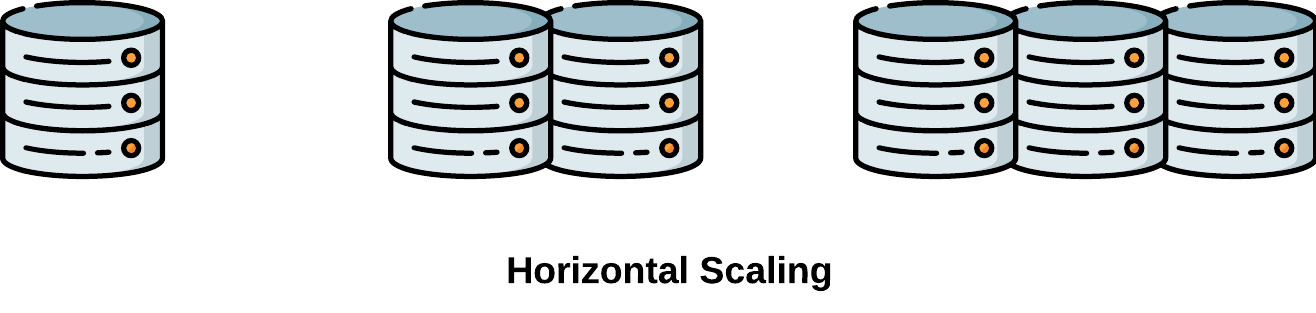
Scaling to handle an increased workload can be implemented in two main ways: vertical and horizontal scaling.
Vertical Scaling, or scaling "up," involves adding resources to a single node. This typically involves upgrading the hardware, such as incorporating more powerful processors, expanding storage, or increasing memory. While it offers a straightforward way to enhance a node's performance, there are limits to how much a single node can be improved in this manner [13].
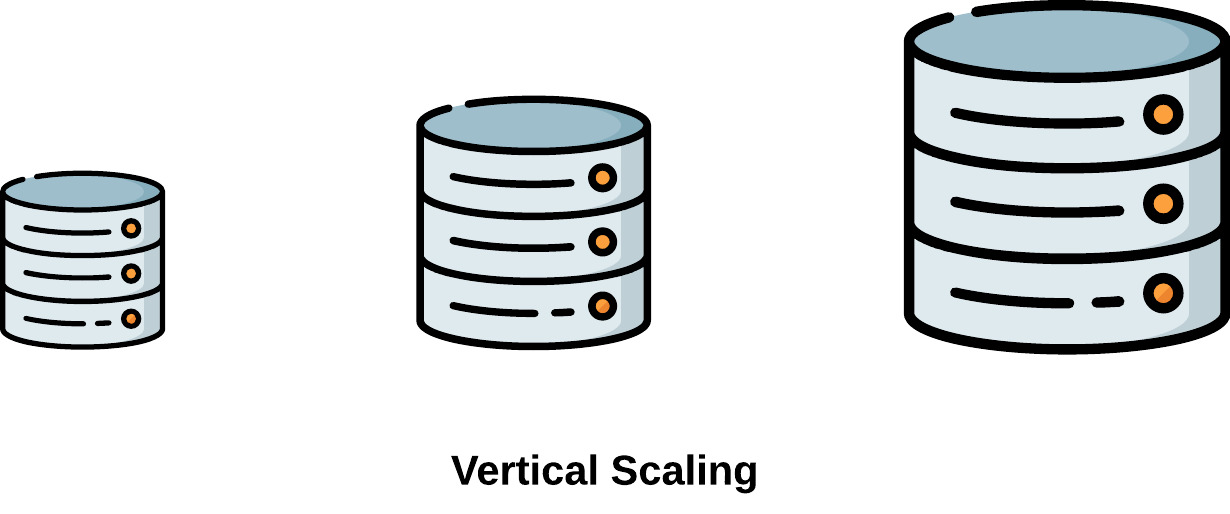
Horizontal Scaling, also known as scaling "out," involves adding more nodes to a system. Instead of amplifying the capacity of a single node, horizontal scaling distributes the workload across multiple nodes. This approach provides a potentially limitless solution for handling increased loads. It also enhances redundancy and fault tolerance, ensuring that the failure of one node does not bring the entire system to a halt [13]. Due to its near-limitless scaling potential, this case study will focus on horizontal scaling.
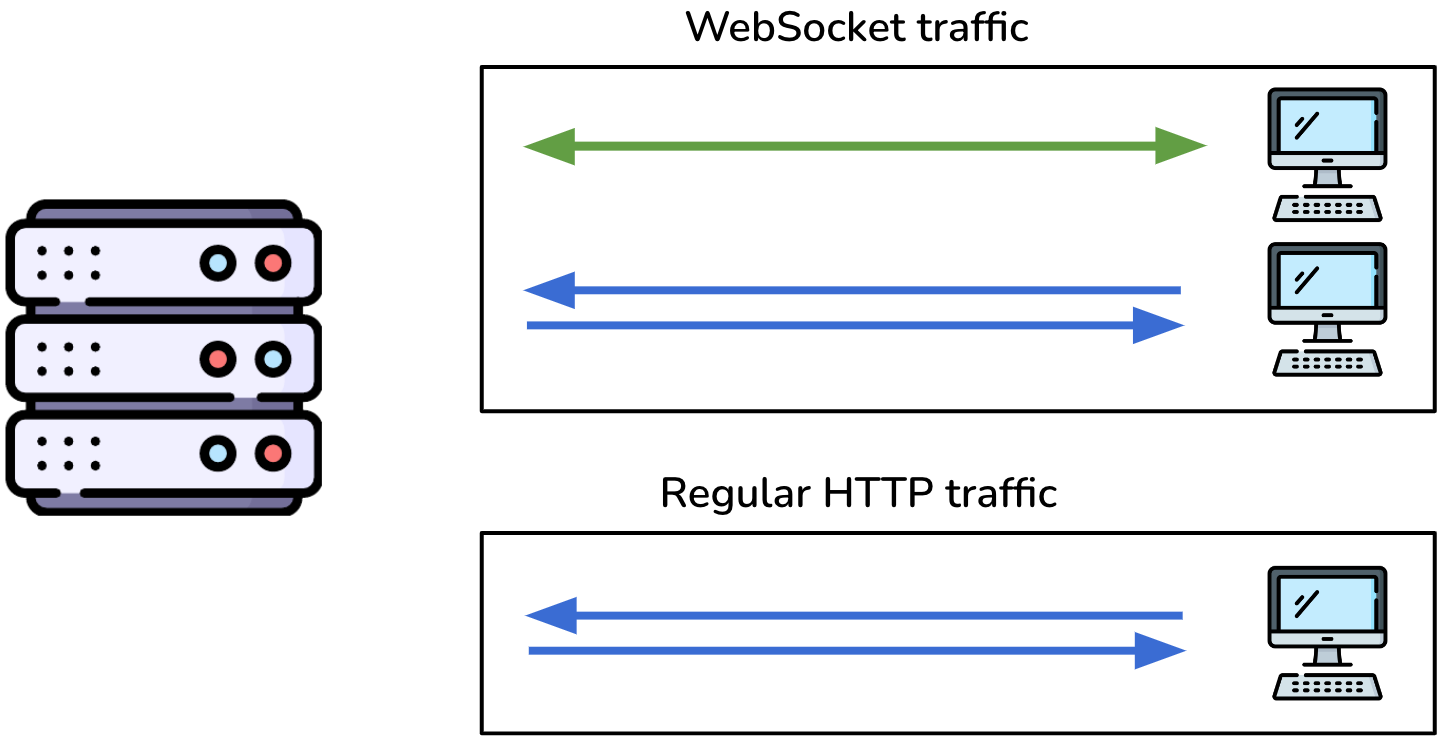
3.1.2 Scaling for Real-time with WebSockets
WebSocket connections are long-lived and continually use server resources. In contrast, server resources are quickly used and then freed up by short-lived HTTP traffic.

In addition to maintaining long-lived connections, a WebSocket server must account for the overhead of new WebSocket connections, which are established with HTTP before being upgraded to the WebSocket protocol.
That means a WebSocket server must handle bursts of traffic from new connections and thousands of concurrent connections, two traffic patterns instead of one. Bandwidth usage can also be substantial when sending data to thousands of concurrent WebSocket connections.
For these reasons, a node serving primarily HTTP traffic, but also WebSocket traffic, has additional resource usage and scaling considerations.
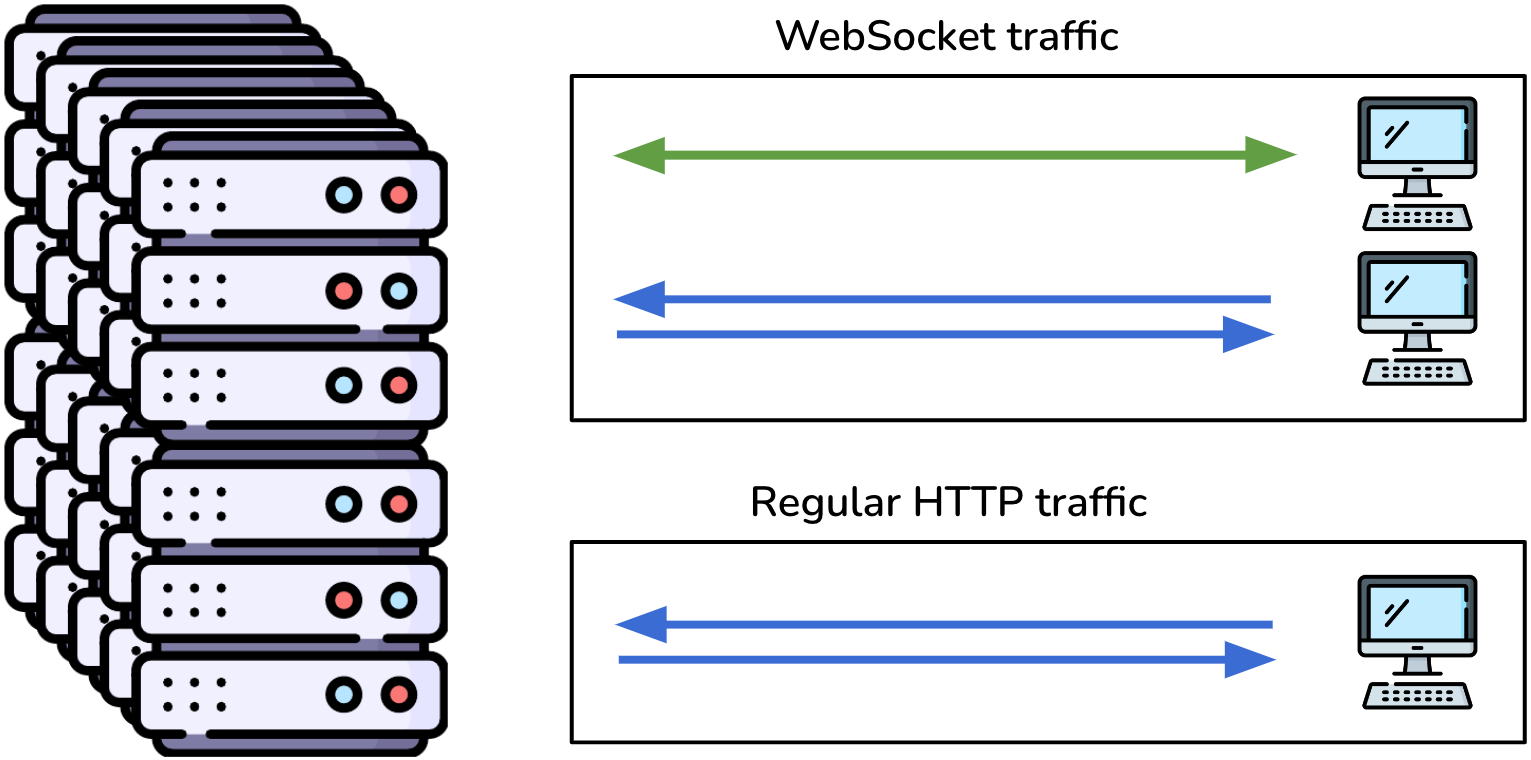
Such a node would have to scale up to accommodate its primary HTTP traffic and the additional WebSocket traffic. This type of scaling is not optimized for either protocol, thus wasting resources and incurring unnecessary costs. Since a server's aggregate WebSocket connections would require more resources than the HTTP connections, such a configuration would be overkill for a primarily HTTP-based application.
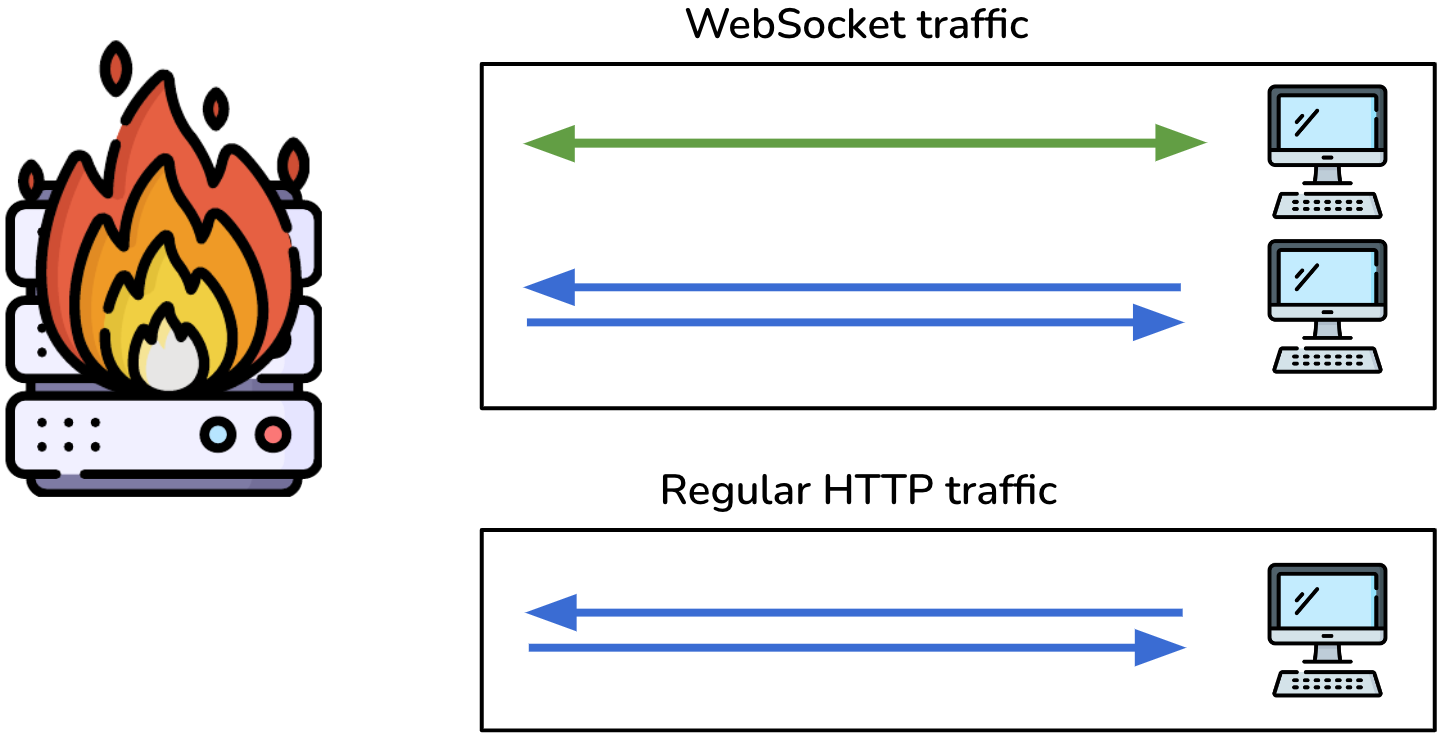
In the worst-case scenario, the HTTP cluster's auto-scaling triggers do not adequately account for WebSocket traffic, and users experience a service disruption.
In short, persistent, long-lived WebSocket connections require an environment that sustains and transmits data to concurrent connections while preserving capacity for new connections.
3.2.0 An Independent Infrastructure for Scaling
The challenge of scaling WebSocket connections can be delegated to a real-time service. This real-time service independently scales to accommodate WebSocket traffic, taking the load of long-lived WebSocket connections off the main application server.
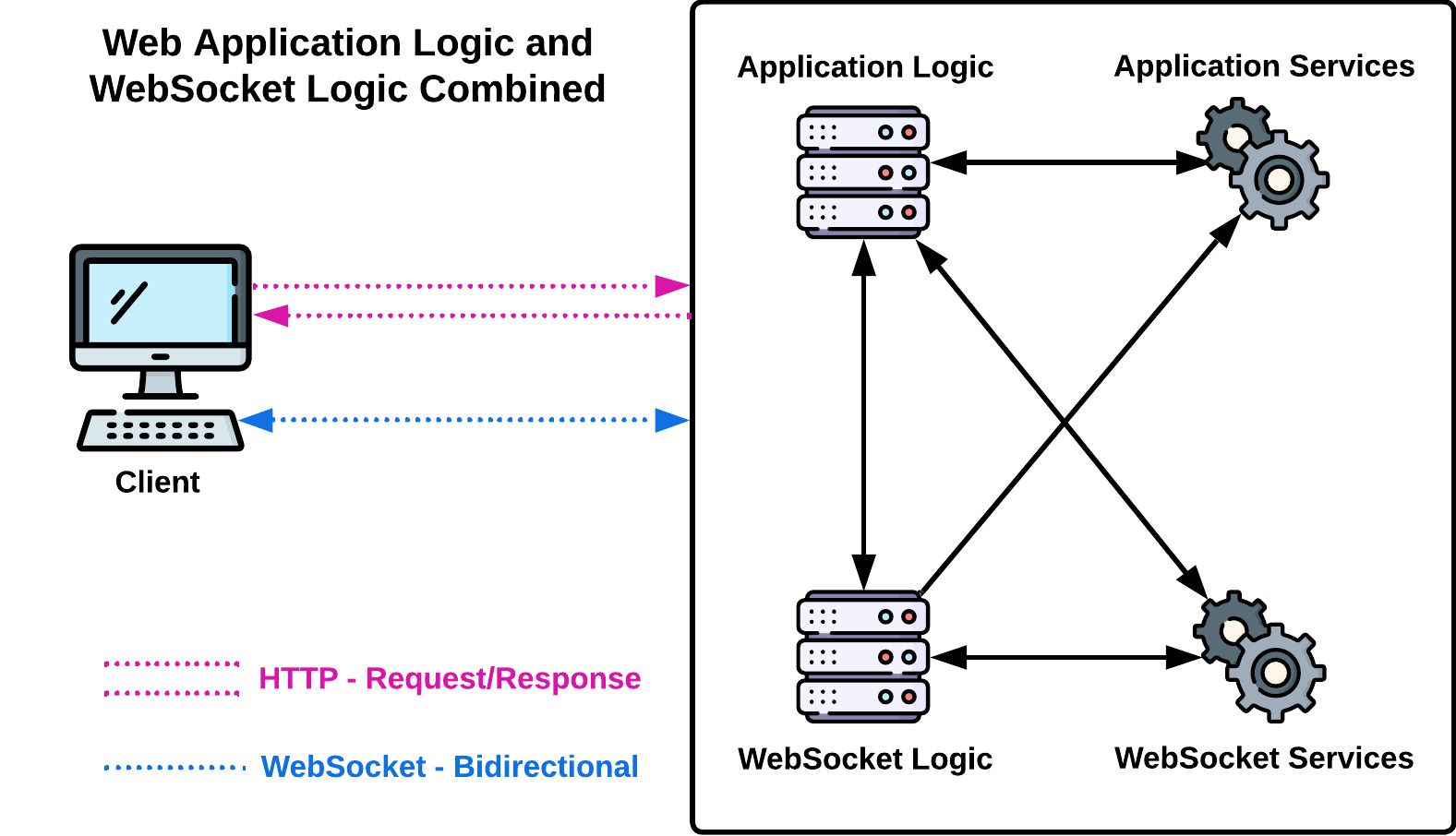
Separating WebSocket traffic from the main application server in this way allows the two node clusters to scale independently. This is advantageous because each cluster can use hardware and auto-scaling triggers designed for one protocol's traffic load pattern and resource usage.
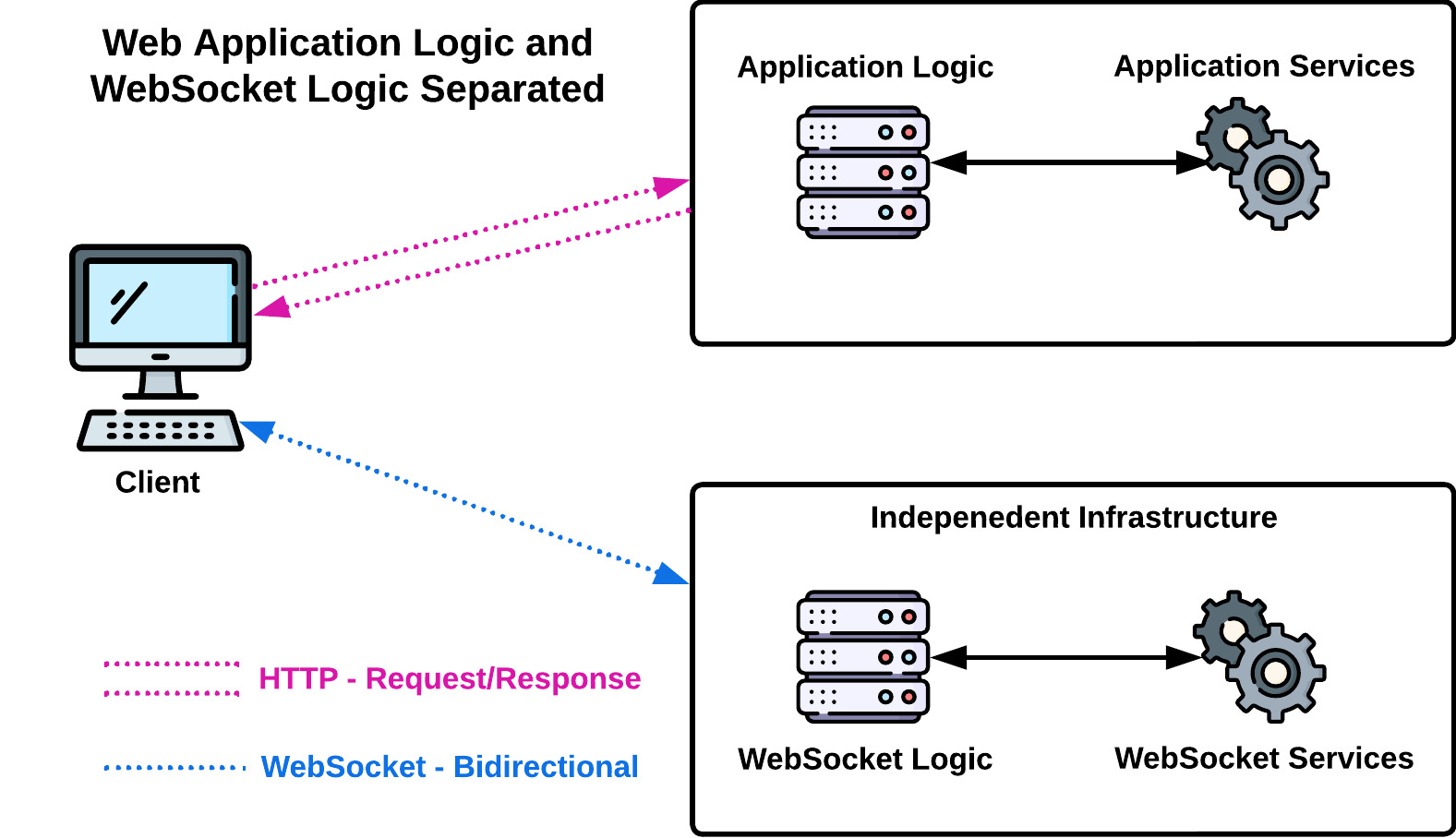
This approach also aligns with the fundamental software engineering principle of keeping different aspects of an application isolated, making the system more robust, flexible, and easier to manage. Developers can now focus on enhancing the application's business logic without getting bogged down in real-time implementation details. This is why we built Twine as a dedicated infrastructure that abstracts away the complexity of maintaining WebSocket connections.
3.3.0 Dropped WebSocket Connections
WebSocket connections may be interrupted at some point in their life cycle due to poor internet or network conditions. Additionally, a WebSocket connection may drop due to client-side proxies and firewalls or server-side node failures or planned maintenance.e. As mentioned earlier, connection loss is especially a concern regarding WebSockets because, compared to HTTP, WebSockets are more sensitive to network disruptions due to their stateful nature [16].
Dropped Websocket connections become a more significant issue as a system scales and takes on more connections. As mentioned, managing long-lived WebSocket connections requires server resources - like CPU and memory - to establish and maintain WebSocket connections as we scale. At a particular scale, unexpected surges in traffic can lead to server overload and, ultimately, dropped WebSocket connections.
When a WebSocket connection drops, this can lead to data loss if data is still in transit when the dropped connection occurs. As mentioned earlier, this is a particular issue for systems prioritizing data integrity.
An example of a system that prioritizes data integrity would be a live chat over a telehealth communications platform; in this case, data loss can lead to a degraded user experience and confusion over important patient instructions. Similarly, data loss on a real-time financial platform can result in poor business decisions. One needs to consider strategies to mitigate or eliminate data loss for these particular use cases.
3.4.0 Connection State Recovery
Applications requiring stringent data integrity, such as the telehealth communications platform mentioned earlier, demand the ability to effortlessly resume the data stream - or connection state - from the exact point of interruption. This ability is called connection state recovery.
Within the context of a real-time service like Twine, connection state recovery is crucial to mitigating data loss. Our aim is to provide users with uninterrupted real-time communication, ensuring that data is not lost in cases of dropped WebSocket connections. A real-time service emphasizing reliability should acknowledge and plan for potential network interruptions.

When a user's WebSocket connection drops and reconnects, a new WebSocket connection is established with the server. A new connection means, by default, the reconnecting user is treated as brand new, and their context within the application is lost. Without any mechanisms such as connection state recovery in place, any data sent while they were disconnected will not reach them.
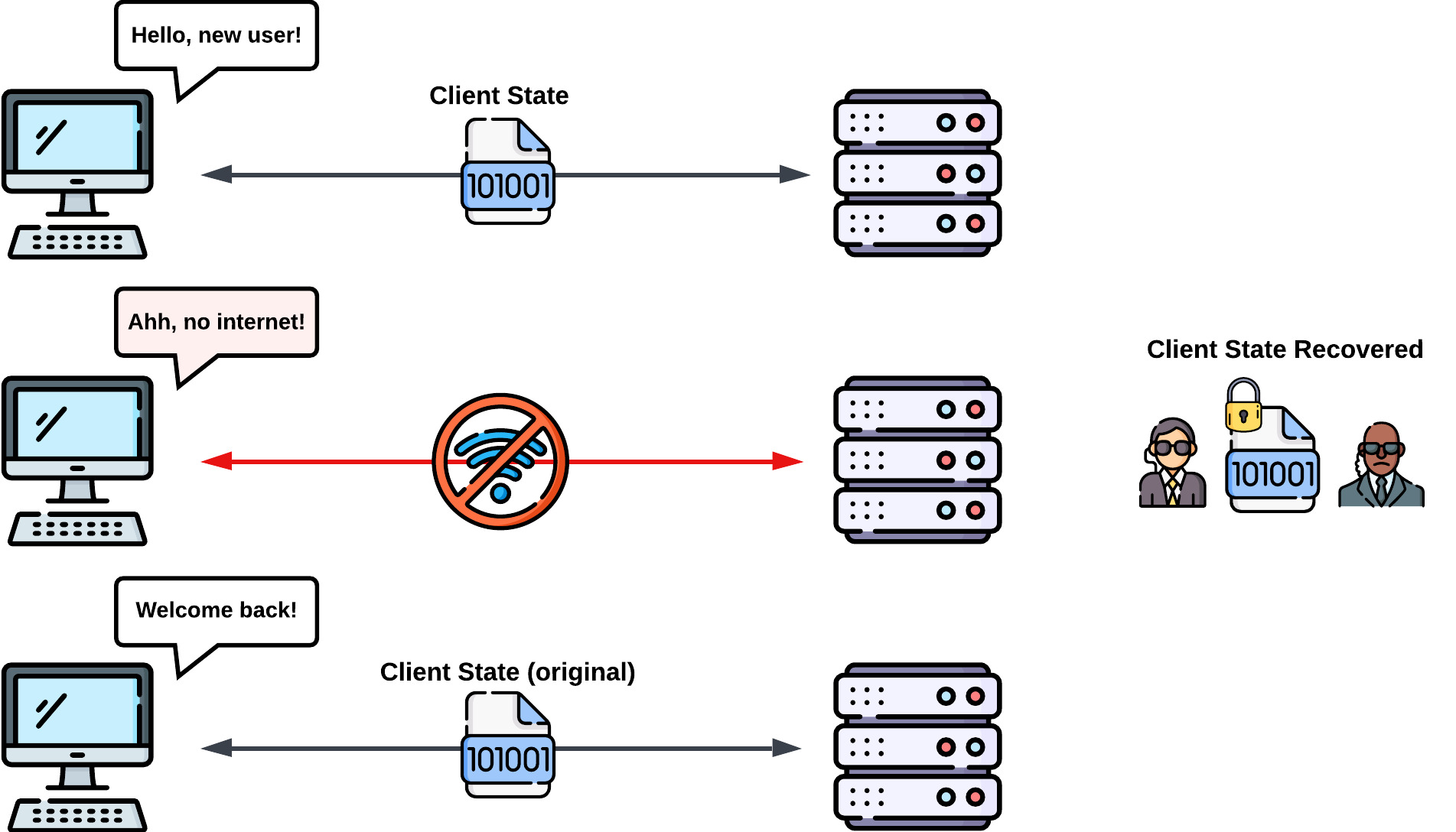
In contrast, when a user disconnects from a service with a connection state recovery mechanism in place, they are returned to their previous context within the application. This means that missed data is delivered to the user in the order that it was originally sent.
4.0 Comparing Existing Solutions
To summarize, we set out to build Twine as a drop-in Real-time As A Service that:
- Recovers lost data in the event of a dropped WebSocket connection using connection state recovery.
- Provides a scalable real-time infrastructure that takes the ongoing server resources required to maintain WebSocket connections off of an application's main server.
There are several existing solutions to these challenges; for example, Ably stands out as an excellent choice among enterprise solutions. On the open-source side, the Socket.IO library has helped millions of developers implement WebSockets.
Together, Ably and Socket.IO provide everything that Twine provides, and more. But comparing them side by side shows a service gap that Twine fills.
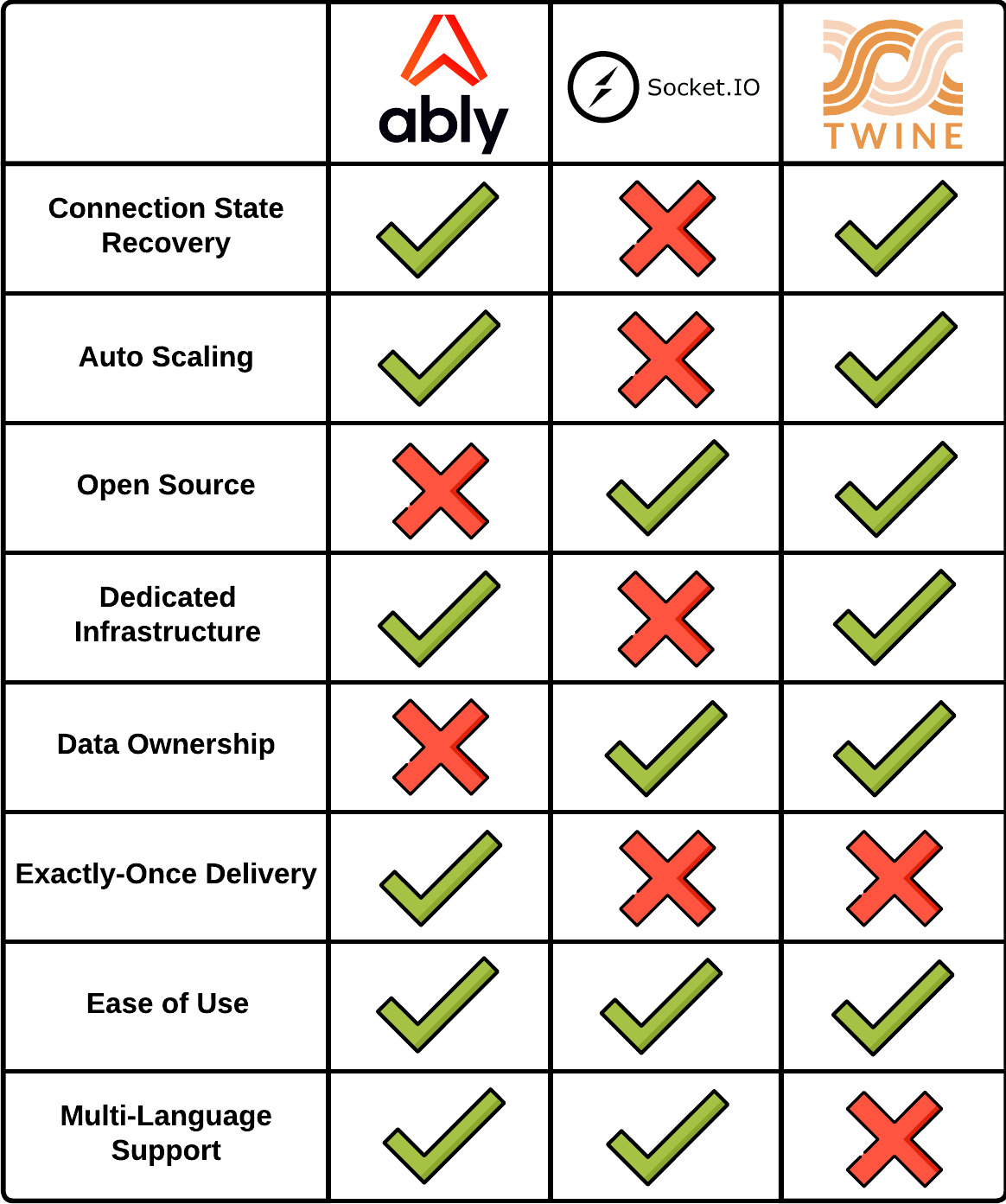
We chose 8 comparison points for Ably, Socket.IO, and for Twine. The first two points connection state recovery and auto-scaling were previously discussed in sections 3.4 and 3.2 respectively.
- Open source was chosen as a comparison point in consideration of projects where cost and transparency are significant concerns.
- Dedicated infrastructure is an important point because it means the service handles WebSocket traffic, instead of the main application's servers.
- Ownership of the data stored in a WebSocket service can be a major consideration, leading to privacy and accessibility tradeoffs.
- Exactly once delivery is another non-trivial consideration. This refers to a service requiring acknowledgment that a client received published data. If the acknowledgment is not received, the service will keep trying to send the data.
- Ease of use. Is the service easy to set up and use? How much configuration is required? This is always a factor in choosing which tool to work with.
- Finally, multiple language support allows more developers and applications to use a WebSocket support service
An additional point here is that Socket.IO is a library that requires developers to implement what they need. For example, Socket.IO provides tools for implementing connection state recovery. It does not provide connection state recovery itself.
5.0 Introducing Twine
Reviewing the comparison points, we found a service gap between the open-source yet labor-intensive Socket.IO and the enterprise solution Ably. Socket.IO, while open-source, requires more effort from developers, and Ably, though reliable, is a paid service that takes control away from developers [23].
Twine fits between the two as an open-source, reliable Real-time as a Service that gives developers full ownership of their WebSocket code and data.
As we can see from those comparisons, Twine does not offer multiple language support or exactly-once delivery. Thus, applications written in a language other than JavaScript or those that require exactly-once delivery should not consider Twine.
Twine was designed for small to medium-sized applications where WebSocket scaling and dropped connections are paramount concerns.
6.0 Evolution of Twine's Architecture
In this section, we will discuss the steps we took to build Twine. This includes how we achieved connection state recovery, built out Twine's infrastructure, and the design choices and tradeoffs we made along the way.
6.1.0 Twine as a Pub Sub Hub
Twine is built off of the publish-subscribe (pub/sub) messaging pattern. With the pub/sub pattern, data is streamed over channels also referred to as queues or rooms. Rooms are an intermediary between publishers and subscribers and often represent a particular category of data. A publisher sends data to a room and any subscribers subscribed to that room will receive the data [30].
The benefits of pub/sub is that it decouples publishers from subscribers; publishers can send data to any number of rooms without knowing anything about the subscribers and subscribers can subscribe to and receive data from any number of rooms without needing to be connected directly to publishers. The middleman, often referred to as a “pub-sub-hub”, maintains a single connection with each of the publishers and subscribers. A publisher sends data to the hub and then it is emitted to all of the relevant subscribers.
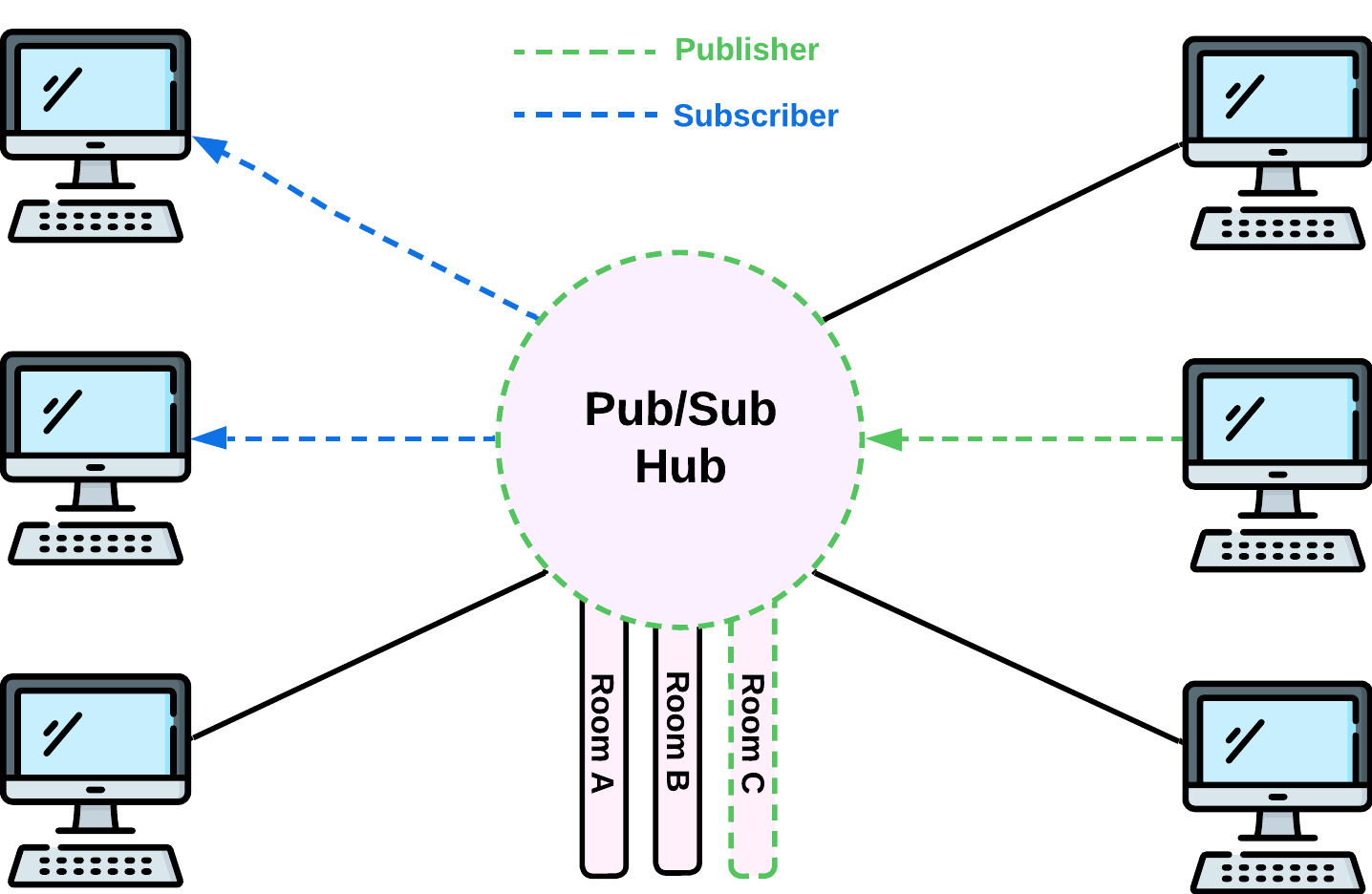
Twine is meant to drop into an application's existing architecture as a layer between clients and backend servers. Backend servers publish data to the Twine server via HTTPS, indicating what room(s) they are publishing to. Twine then sends that data to the clients subscribed to the relevant room(s) in real-time via a WebSocket connection.
Thus, we started building Twine as a single Node.js process capable of accepting data published via HTTP POST requests from backend servers and sending that data to clients via WebSocket connections. Twine establishes and maintains these WebSocket connections with clients and also implements the rooms pub/sub functionality previously mentioned. We built Twine's Server using TypeScript, Node.js, Express, and the Socket.io library.
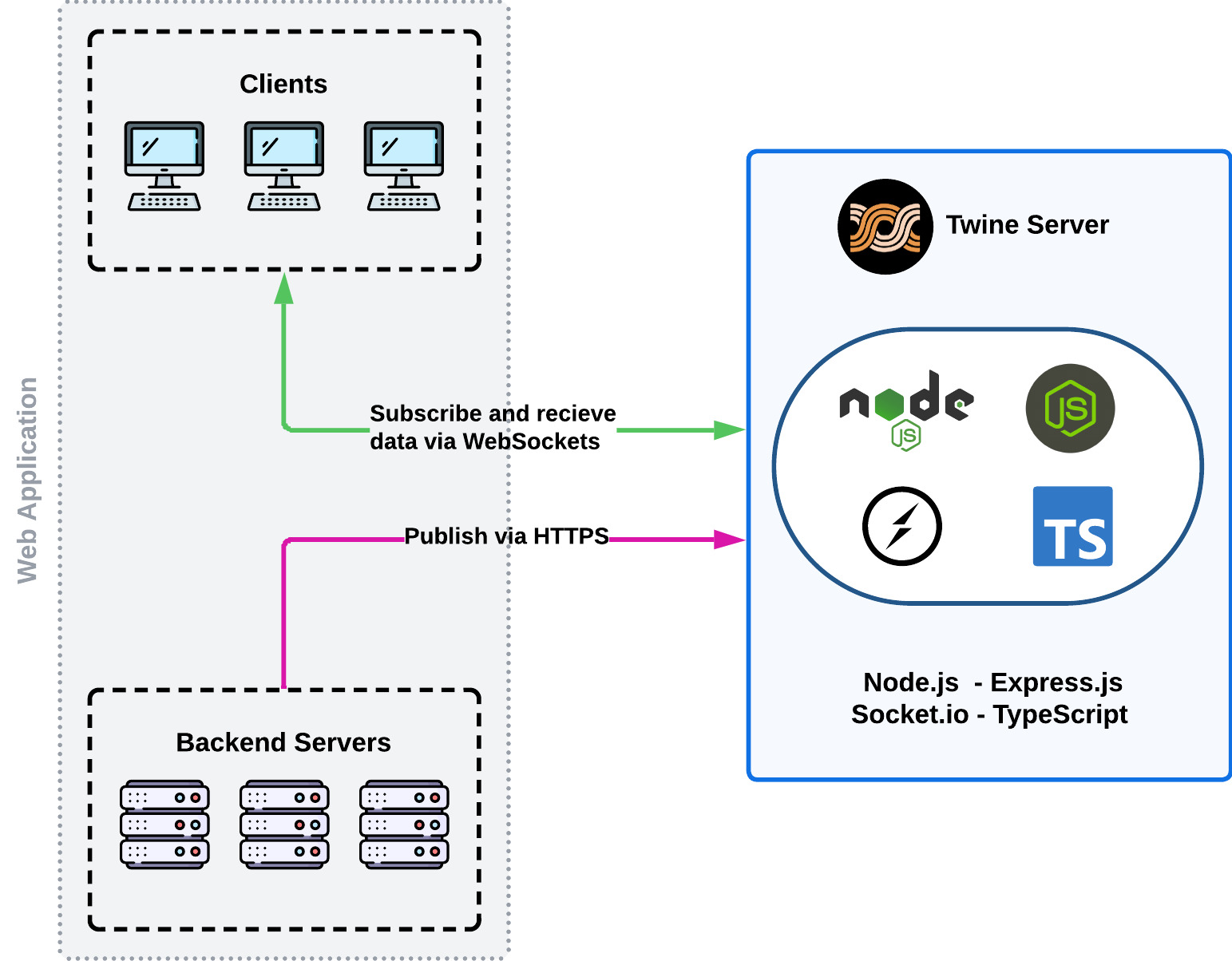
6.2.0 Implementing Connection State Recovery
At this point in our build process, we needed to decide how we would implement connection state recovery.
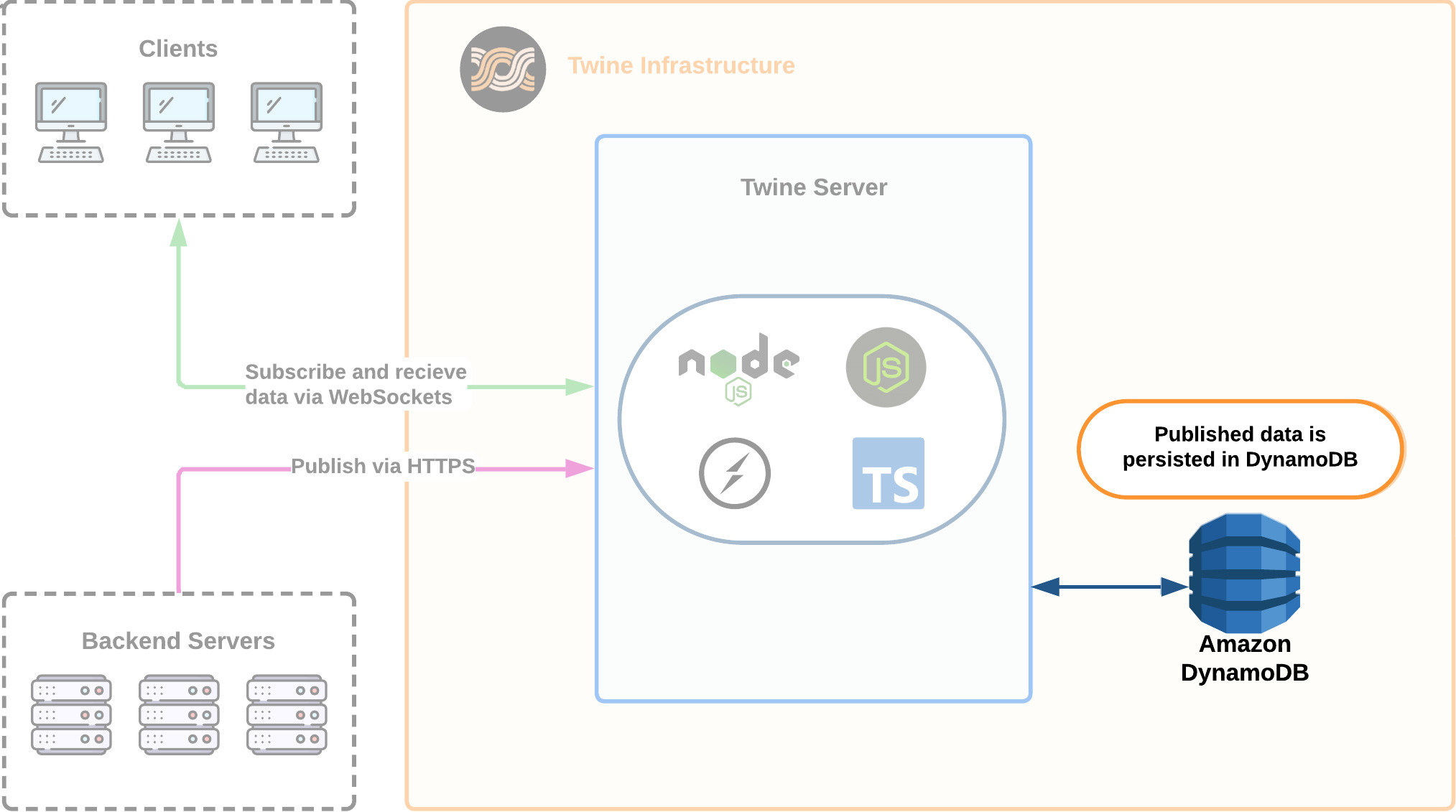
6.2.1 Storing published data in DynamoDB
We knew we needed a place to store data published from the backend servers to the Twine server. Since Twine focuses on reliability in the form of connection state recovery, we knew we needed to ensure data is placed into a persistent data store. We decided to use DynamoDB since we eventually knew we wanted Twine to deploy on Amazon Web Services (AWS).
AWS currently holds 33% of the market share for cloud infrastructure [24]. We wanted Twine to be easy to use and deploy so while we knew adding AWS would add some complexity to our process of creating Twine, we were willing to make this tradeoff.
Specifically, DynamoDB provides the following advantages:
- DynamoDB is a NoSQL database and therefore has a more flexible schema compared to relational databases. This provides Twine's users the flexibility to send and store any type of data from backend servers.
- NoSQL databases provide faster lookup times.
- When compared to AWS NoSQL alternatives such as DocumentDB, DynamoDB uses a key-value structure that aligns with Redis, which we knew we wanted to use as a cache eventually, ensuring consistent data storage across both systems.
6.2.2 Using Cookies
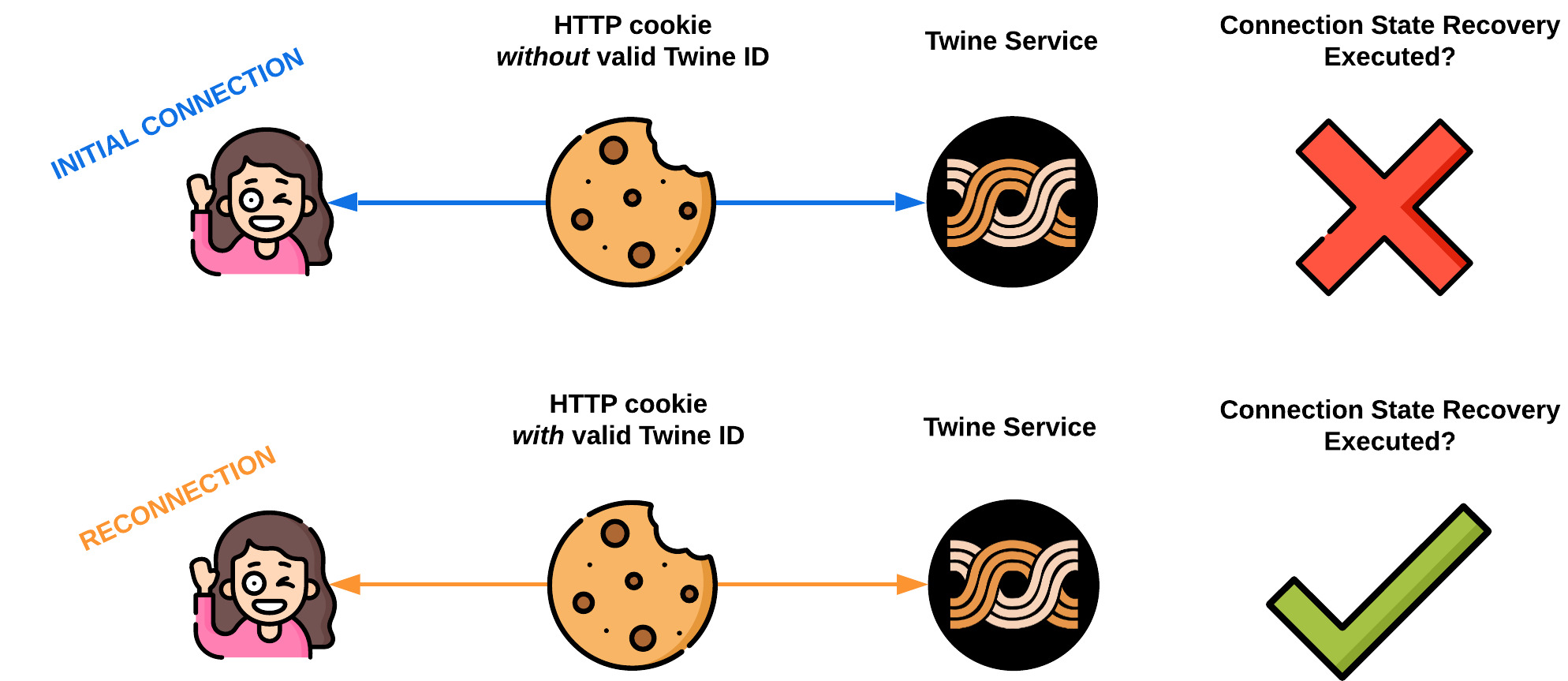
When the Twine server receives a request from a client to establish a WebSocket connection, Twine will take different actions based on whether this request is an initial request or a reconnect after a dropped WebSocket connection.
If a client is connecting for the first time, an initial fetch request is sent to the Twine server. The Twine server listens for this request and upon receiving it, sets a client-side persistent cookie. This cookie stores a randomly generated uuid referred to as the twineid. The twineid persists on the client between reconnects.
Thus, if a client is reconnecting to the Twine server after a dropped WebSocket connection, this twineid will be able to be retrieved from the client-side cookie. If the twineid is present, the client is classified as a reconnect, and connection state recovery will execute.
6.2.3 In Order Delivery of Data
If a client is re-connecting to the Twine Server, we need to determine what data, if any, the client missed while disconnected. With in-order delivery of missed data being our goal, we utilized the timestamps of the published data and the client's session to implement this logic.
When published data is stored in DynamoDB, we also store the channel the data was published to and a timestamp representing when it was received by the Twine server.
When a client is first connected to Twine and receives data, a session is created. This session captures:
- the user's
twineid - the channels they're subscribed to and
- the timestamp of the last data they successfully received (the same timestamp representing receipt by the Twine server).
The timestamp in the client's session is updated every time the client receives a new piece of data.
As previously mentioned in section 6.2.2, if a client is reconnecting, connection state recovery will execute. This entails fetching their session timestamp - the timestamp of the last data they received - and previously subscribed channels. Both are used to query DynamoDB for data that may have been missed while disconnected.
The query retrieves all data - matching the list of subscribed channels - with a timestamp greater than the given session timestamp. This will be data sent after the last one received by the client, in the order it was originally published to the channel - for each of their subscribed channels.
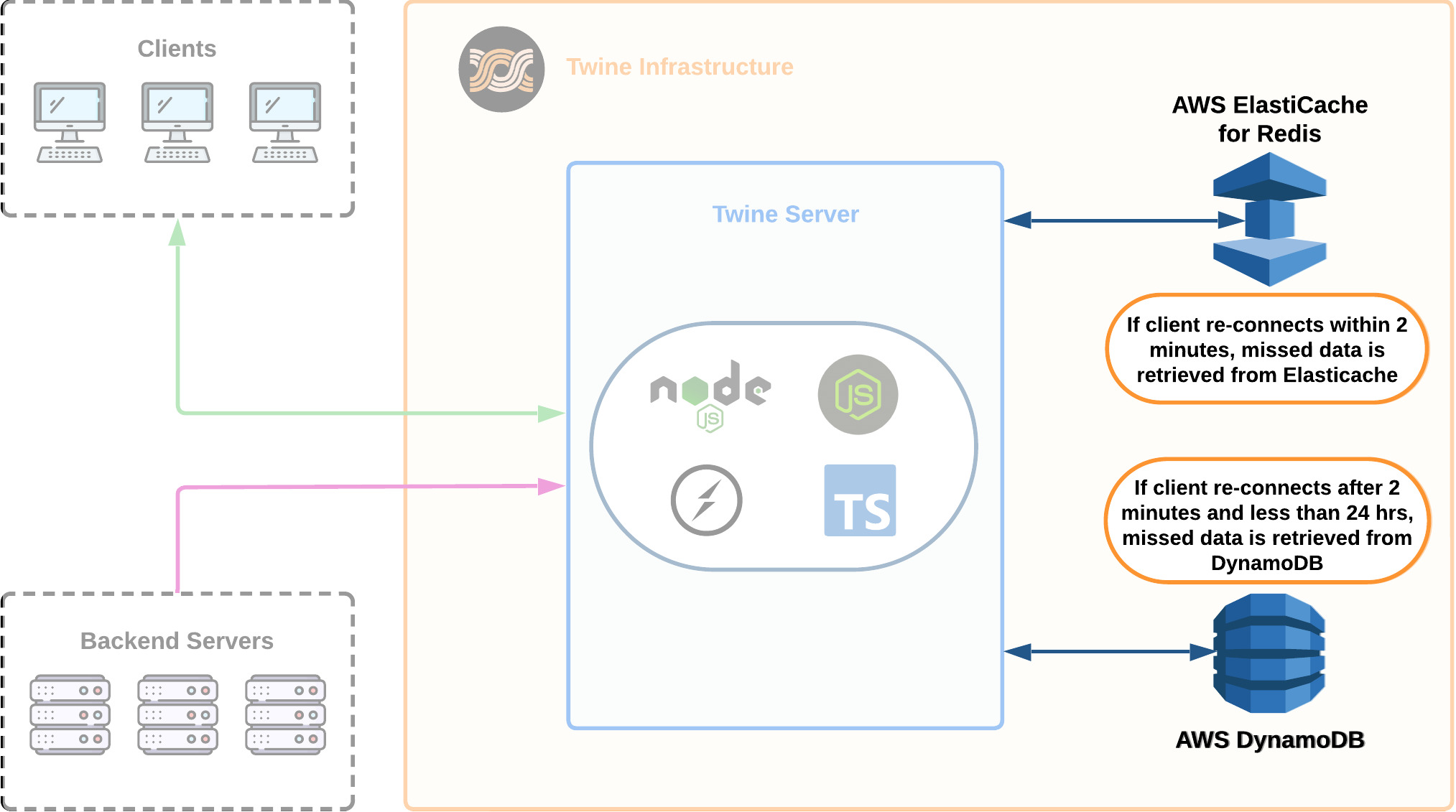
6.3.0 Adding Redis
Now that we achieved our main goal for Twine by implementing connection state recovery, we turned to a secondary goal of making Twine scalable. While we need a persistent data store for our service to be reliable, persistent data stores are slow [25].
To mitigate this we decided to add a Redis cache - AWS ElastiCache for Redis - to help reduce the number of queries to DynamoDB. Compared to a persistent data store which stores data in disk storage, data stored in AWS Elasticache for Redis is stored in-memory which can be accessed much faster. Additionally, Redis uses a key-value data structure that is optimized for quick data retrieval.
We stored messages in the Redis cache for up to 2 minutes. If a client was reconnecting later than 2 minutes after their last disconnect, missed messages would be pulled from DynamoDb. Twine provides connection state recovery for up to 24 hours since the client's last disconnect.
Depending on the service, a limit on the number of messages or the period of time that messages can be retrieved may be required. A service that expects high-traffic volumes or intends to retrieve message data for any length of time may put an unnecessary burden on the system. For example, a user reconnecting after a long period of inactivity may result in retrieving and delivering tens of thousands of messages at once, potentially impacting the performance of the service. For this reason, strategies like limiting the retrieval time or the maximum number of messages may need to be implemented.
6.4.0 Scaling Twine
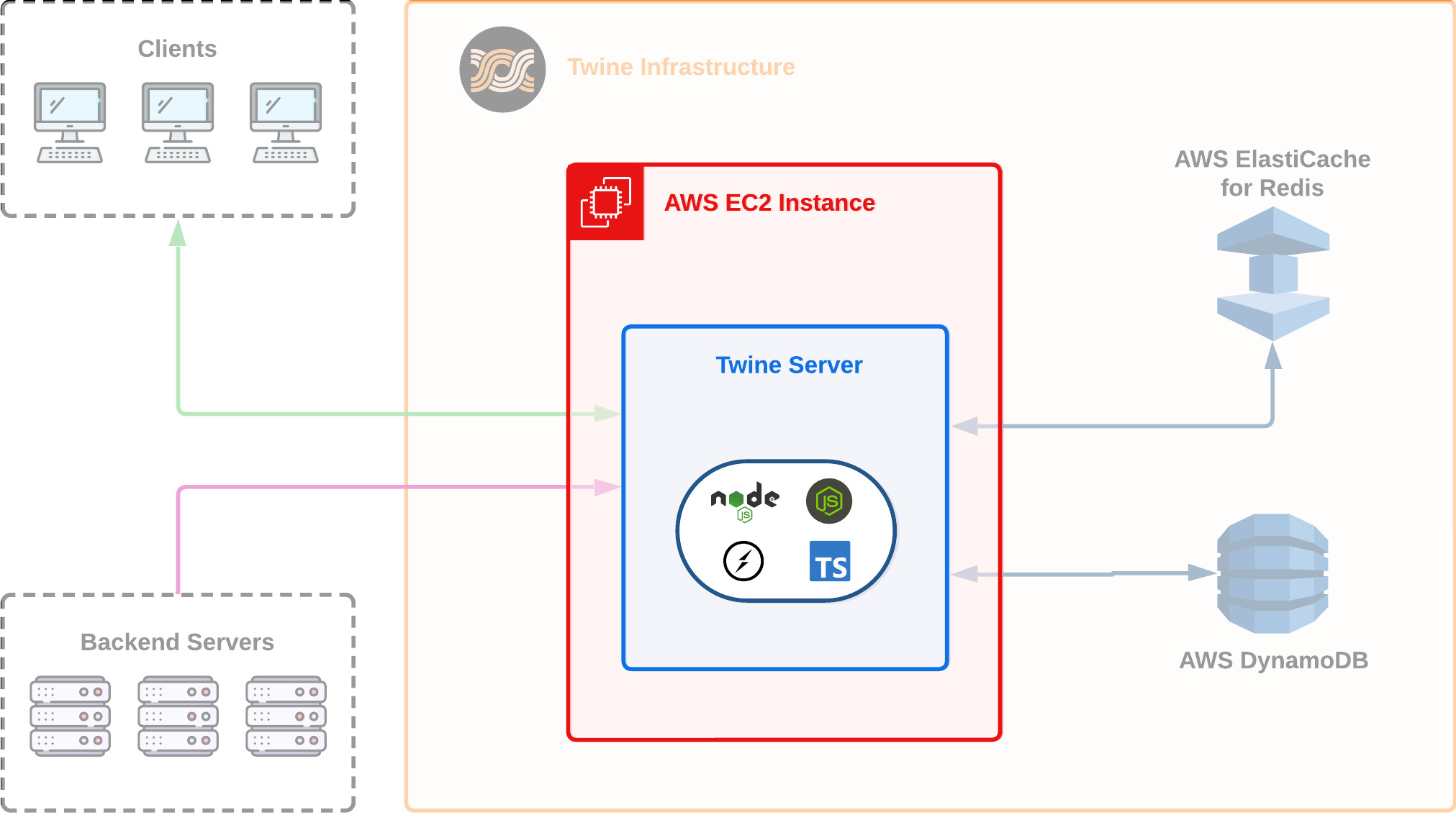
6.4.1 A Single EC2
Since we decided to work with the AWS ecosystem for deploying Twine, we started by getting Twine deployed on a single EC2 instance.
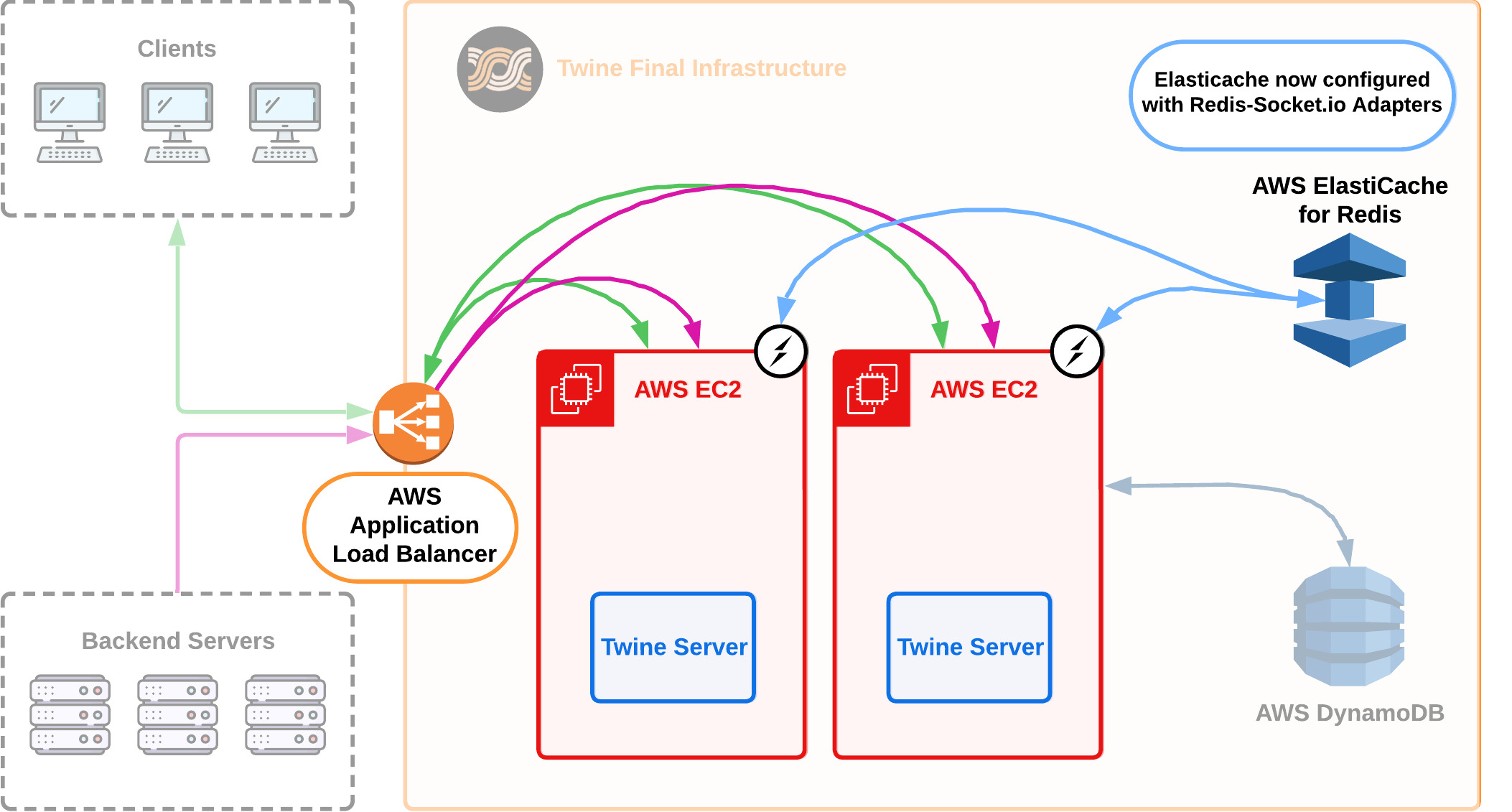
6.4.2 Multiple EC2s
We decided to deploy each Twine service starting with two EC2 instances by default. Firstly for our main goal of reliability; in case one instance of Twine went down we wanted to have a backup. Also for our secondary goal of scalability, we knew we eventually wanted the ability for Twine to scale out horizontally.
In order to distribute traffic amongst our multiple Twine servers we needed to use AWS' Application Load balancer. Additionally, to ensure data published from a backend service was made available to all EC2 instances we needed to enable socket.io's Redis adapter. We will discuss how Socket.IO's Redis adapter makes data available to all EC2 instances in further detail in Section 7.2.2.
6.4.3 Elastic Beanstalk
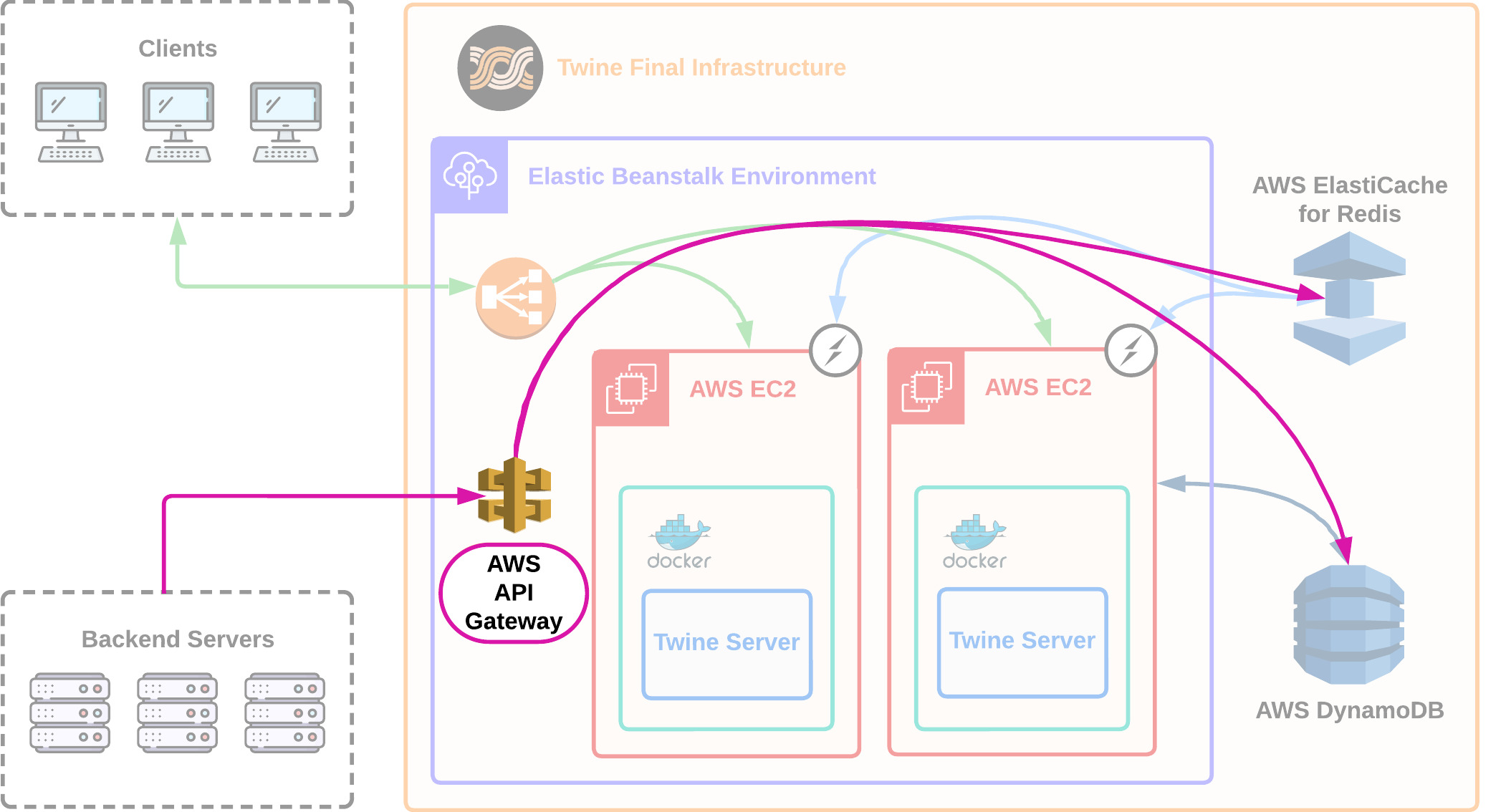
In our final version of Twine's server infrastructure, we have moved from EC2 instances to Amazon's Elastic Beanstalk.
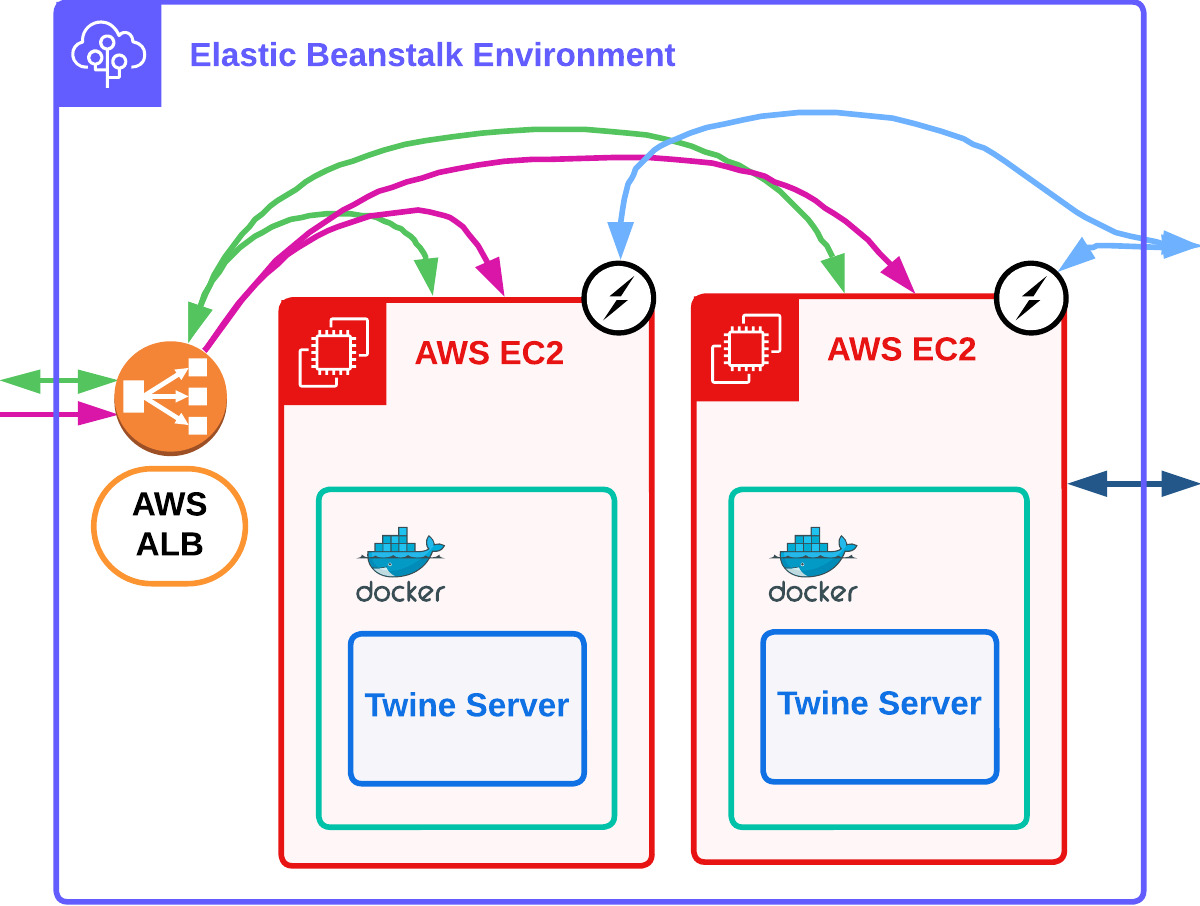
Elastic Beanstalk is a managed platform-as-a-service provided by AWS and allows us to abstract away the complexity of maintaining our EC2 instances ourselves. Elastic Beanstalk automates the deployment of Twine EC2 server instances and an application load balancer for us. It provides autoscaling so that if traffic to instance(s) of Twine's server increases or decreases, new instances are added or removed accordingly. Finally, it provides health monitoring so that if a particular Twine instance fails, a new healthy instance is added in its place [29].
We chose Elastic Beanstalk over other options such as Amazon Elastic Container Service for this ease of use while sacrificing some control. Additionally, we decided to containerize our Twine server logic in a Docker container so that our application and its dependencies would run consistently.
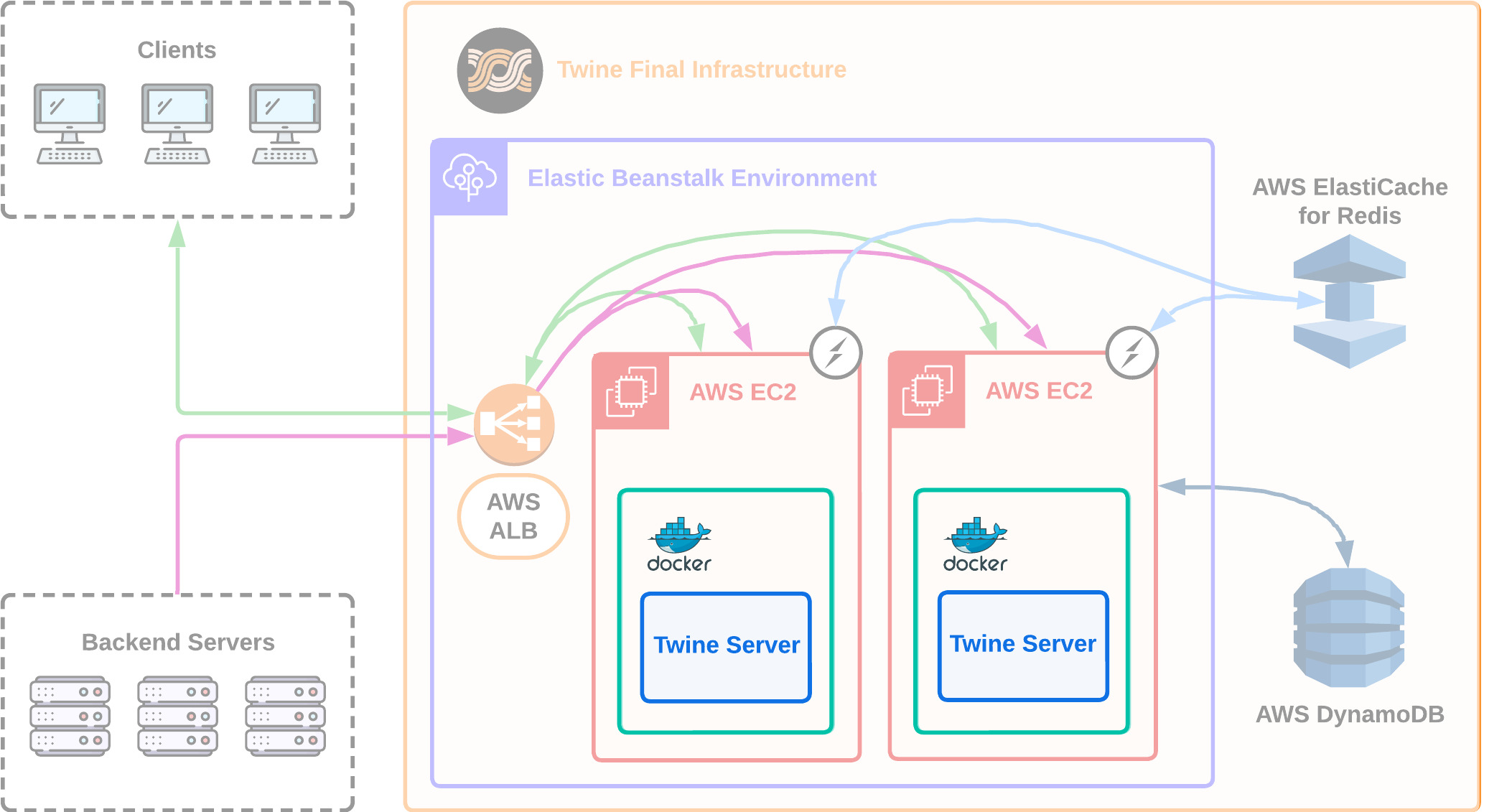
We now have our final architecture of Twine which includes our Twine server logic running in a Docker container on Elastic Beanstalk.
7.0 Engineering Challenges
Now that we've seen how Twine was built, we will take a closer look at the following engineering challenges we faced during the build:
- Storing and securing the twinId on the Client
- Scaling WebSockets to multiple servers
- Load testing
7.1.0 Storing and Securing the twineId on the Client
As discussed in Section 6.2.2, the twineId is a randomly generated uuid that we use to determine whether a client is connecting for the first time or is a reconnection to Twine. However, we needed a way to store the twineId on the client for this logic to work.
To meet our needs, we looked into mechanisms for storing data on the client, namely localStorage and persistent cookies.
We started out storing our twineId in localStorage. localStorage is a part of the HTML5 specification and a way to store large amounts of data on the client; it is modern and faster than cookies [31]. localstorage persists between client visits and does not expire until it is manually deleted. Since we did not need the twineId to persist beyond 24 hours after our client's last disconnect, we would need to write the logic to delete it manually. Additionally, the data stored in localStorage is not encrypted out of the box, which means additional logic is needed to ensure the twineId was stored securely on the client.
After further research, we discovered that persistent cookies, albeit slower and less modern than localStorage, fit our needs better [31]. Persistent cookies are better used for small amounts of data stored on the client. Additionally, persistent cookies have an expiration date that we could set to 24 hours without any additional logic.
We also chose to use a cookie because of its optional HTTPOnly flag, which blocks client-side scripts from accessing the cookie data. Normally, that is not an issue, but a successful cross-site scripting attack would otherwise be able to read the twineId data in the cookie, hijack the user's session, and access potentially sensitive data, as well as impersonate the user within the application. Twine's HTTPOnly cookie prevents a user's session ID from falling into the wrong hands.
7.2.0 Scaling WebSockets to Multiple Servers
When we moved twine to multiple EC2 instances, we ran into several challenges with scaling WebSocket connections.
7.2.1 Load Balancing WebSocket Connections
When we started using AWS' Application Load Balancer to distribute traffic amongst multiple EC2 instances, we ran into difficulty establishing WebSocket connections due to the process that Socket.io uses to establish WebSocket connections between clients and the Twine server when long-polling is enabled.
Although our primary connection is WebSockets, we can increase the availability of an application by adding a secondary connection type - a fallback - here, that's long-polling.
Suppose a user's WebSocket connection is disrupted. In that case, the client and server will attempt to preserve the connection by downgrading to long-polling. Likewise, if a user cannot connect via a WebSocket connection - due to firewalls or blocking antivirus software - a fallback would increase the likelihood that the application is still available.
When long-polling is enabled as a fallback, Socket.io takes the following actions to establish WebSocket connections by default [32]:
- The client sends an HTTP request to establish a connection via long-polling.
- In response, a 20-character unique identifier (referred to in socket.io documentation as the
socket.id) is generated on the server and sent to the client. - A second HTTP request is sent automatically from the client to the server to upgrade the connection to WebSocket. This request must include the
socket.id. - If the upgrade is possible, the WebSocket connection is established using the same
socket.id, and the long-polling connection is closed—otherwise, the long-polling connection remains open.
The challenge is that the HTTP request to upgrade must be sent to the same server that generated the socket.id. Failure to do so results in a Socket.IO HTTP 400 error, stating "Session Id unknown," leading to a failed connection upgrade and fallback to long-polling [33].
By default, there is no logic (or guarantee) that subsequent requests would be routed to the same server, resulting in these HTTP 400 errors and an inability for WebSocket connections to be established.
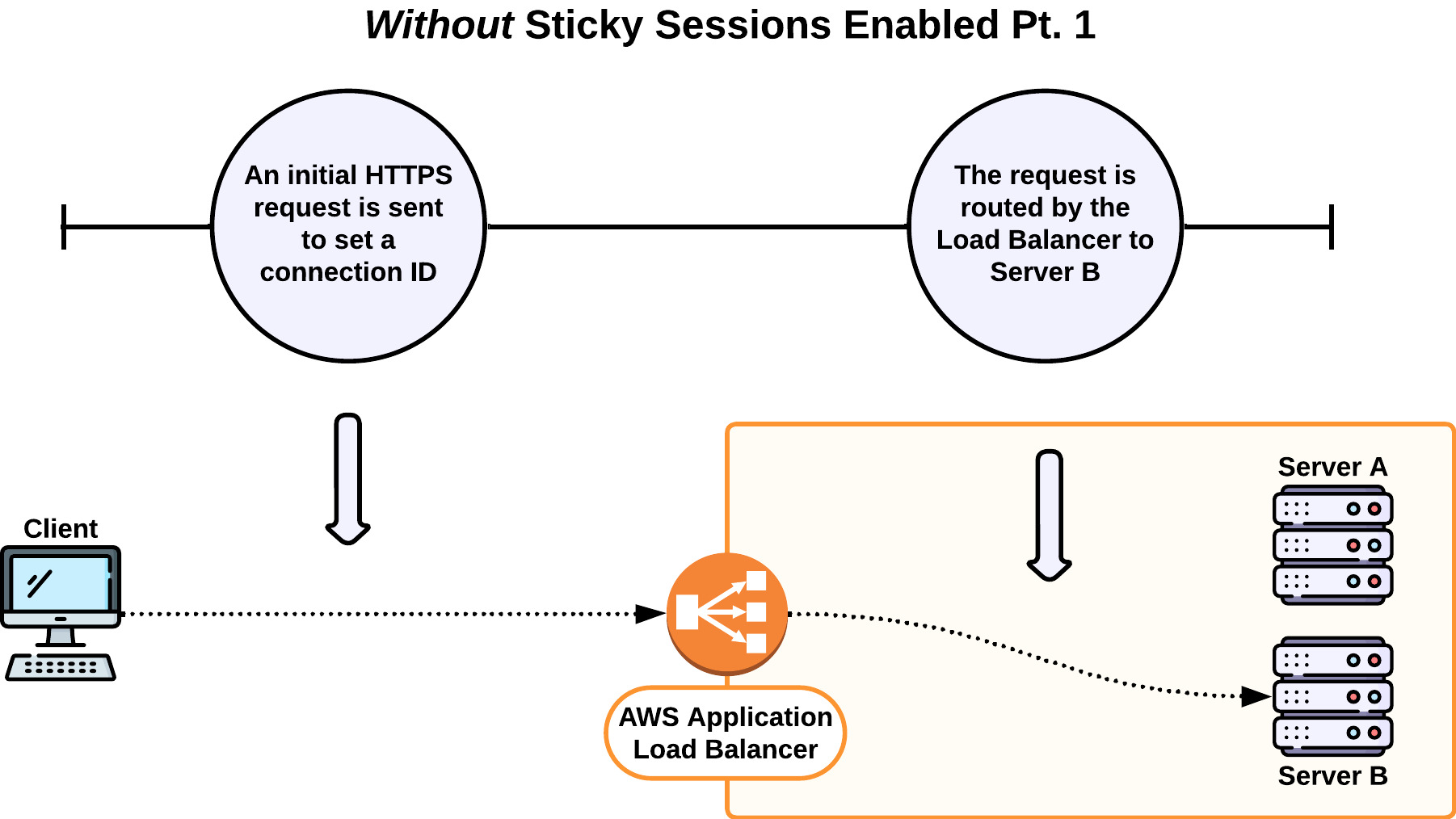
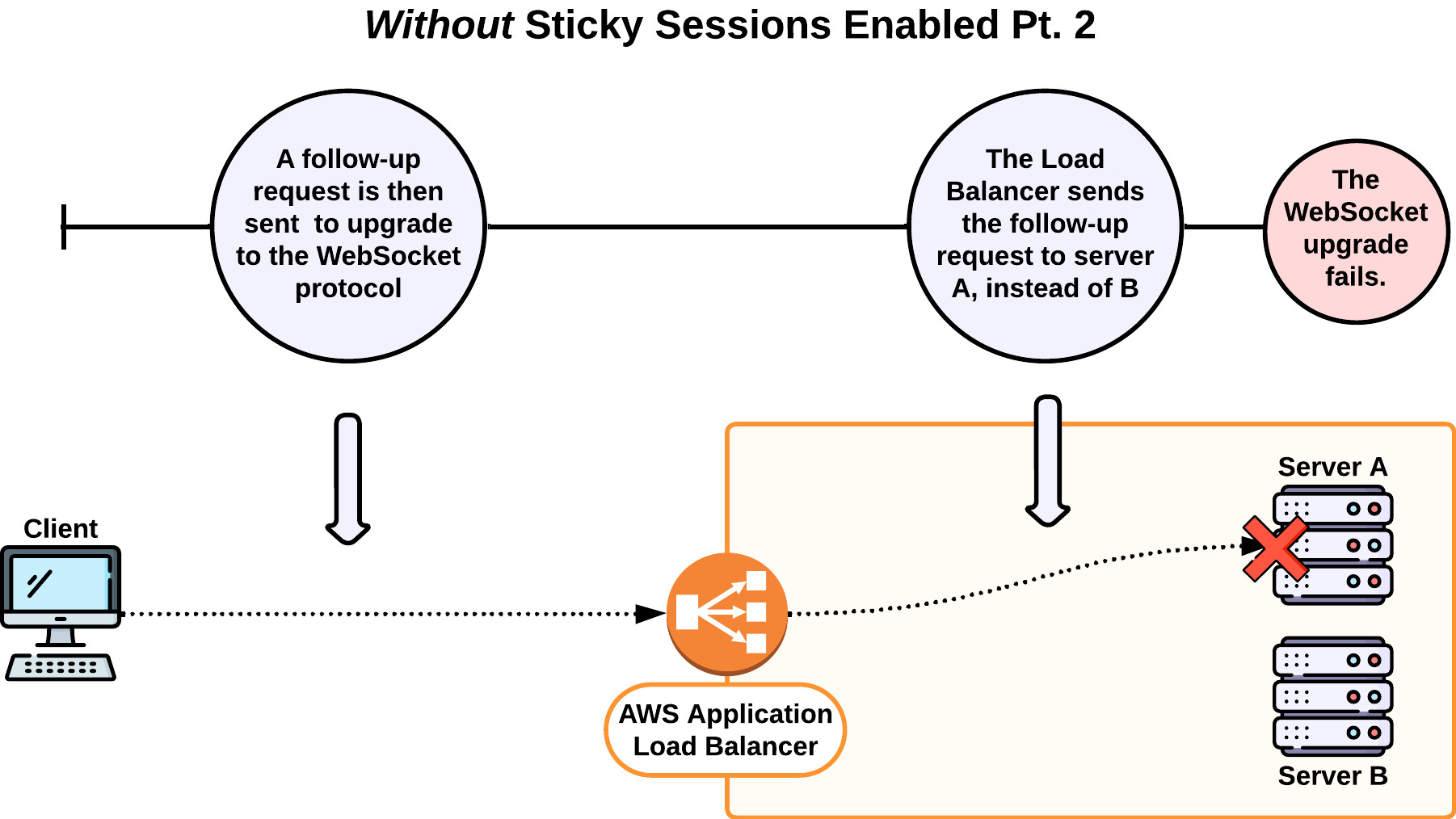
The solution was to enable sticky sessions in our load balancer settings. Sticky sessions are used to bind a user to a specific target server. With sticky sessions enabled, the two initial requests to establish a WebSocket connection went to the same server, and Websocket connections could be established.
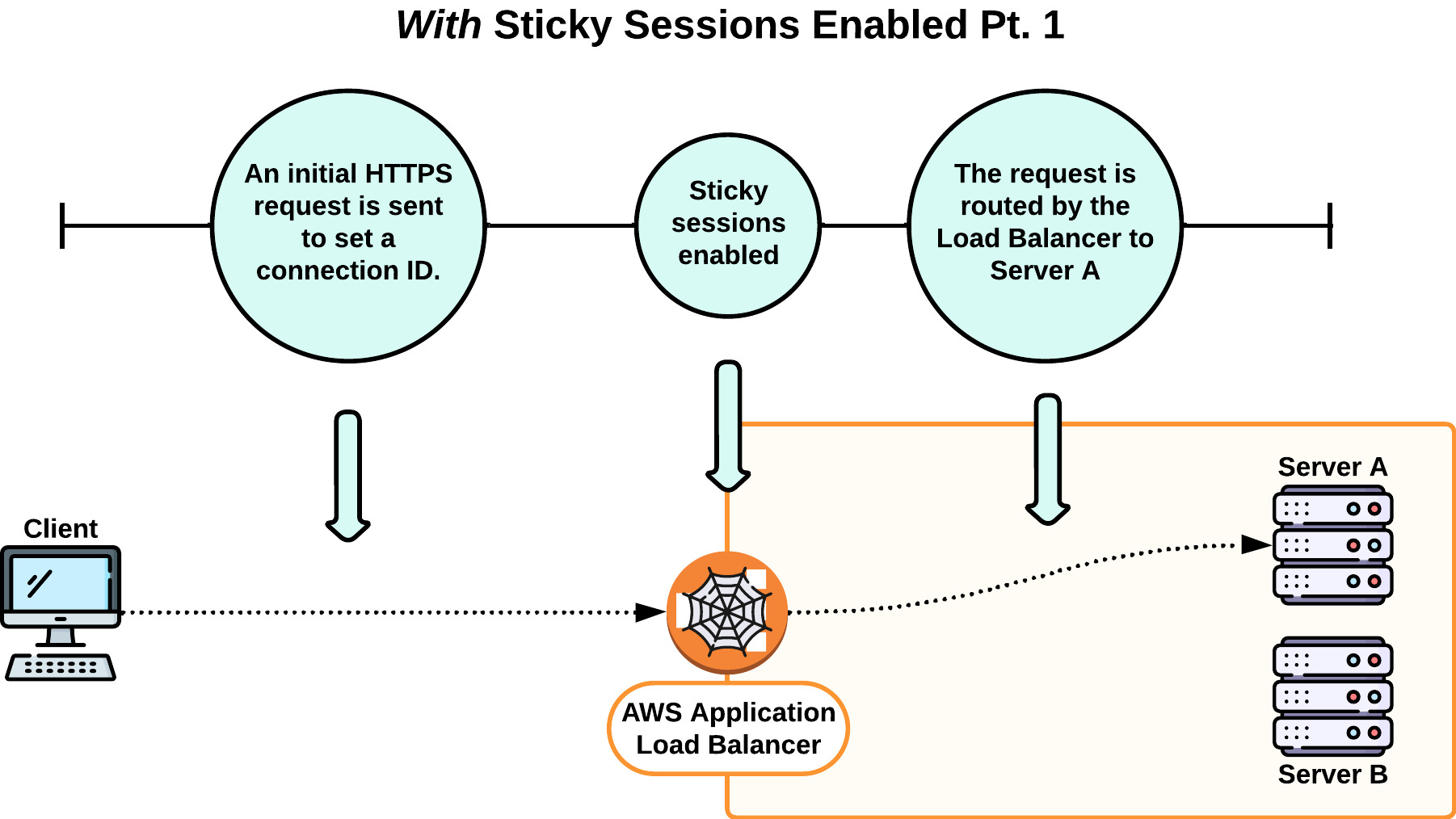
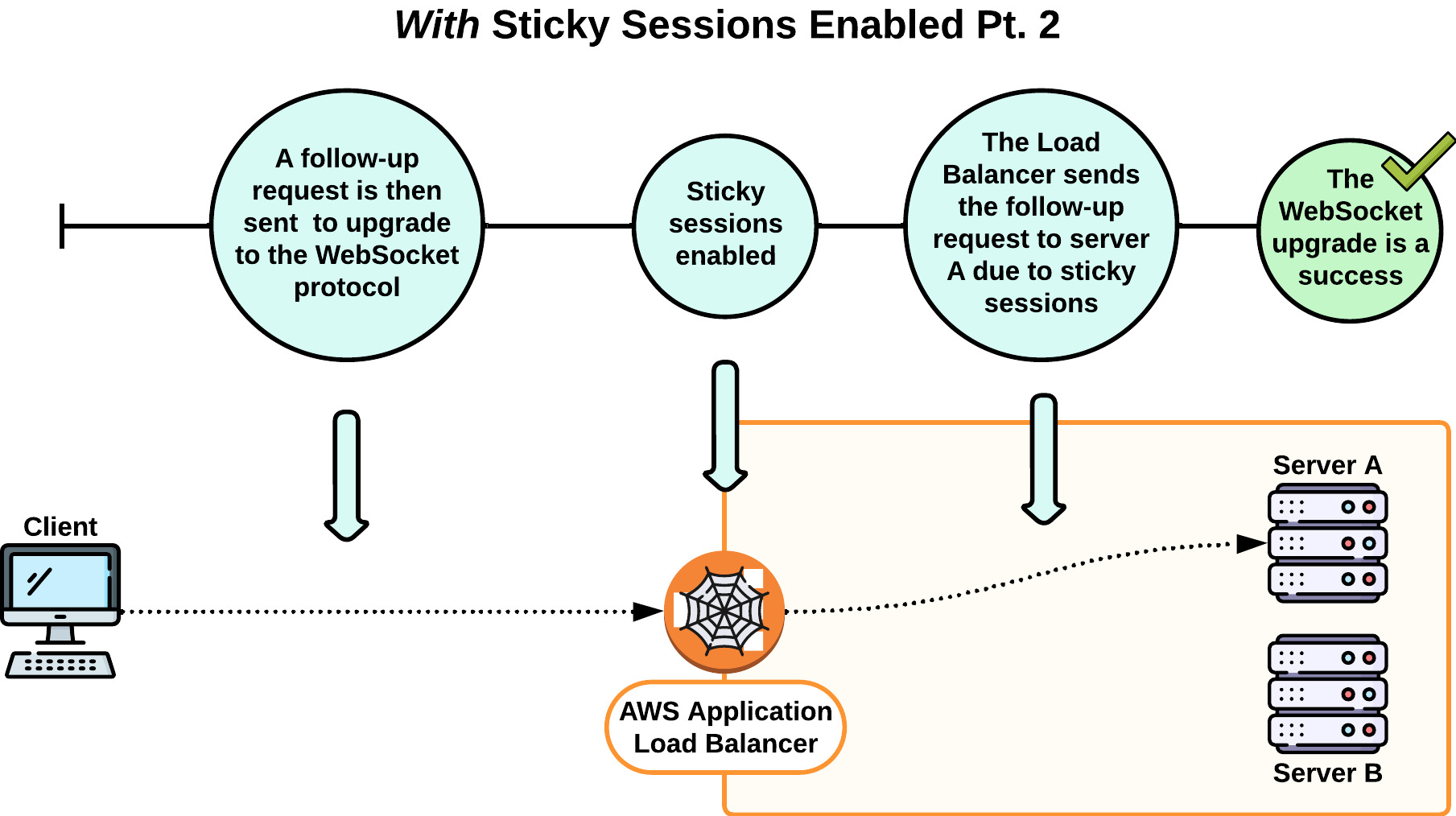
7.2.2 Redis Adapters
Now that we were able to establish WebSocket connections, we encountered another issue while scaling: synchronizing state across multiple Twine Server instances.
In section 8.1 we discussed how each Twine server instance works as a pub sub hub; backend servers send data to a Twine server instance intended for all clients subscribed to a particular room, and then clients connected to that specific server instance and subscribed to that specific room receive that data.
Multiple Twine server instances complicate things because clients subscribed to the same room can now be connected to two different Twine server instances. Additionally, backend servers can now publish data to either of the Twine server instances. To highlight why this is an issue, consider the following scenario:
- We have two clients - Client A and Client B.
- We have two Twine Server instances - Server A and Server B.
- Client A is connected to Server A, and Client B is connected to Server B.
- Both Client A and Client B are subscribed to Room C.
- Data is published from backend servers to Server A intended for all subscribers to Room C. Server B, however, has no way of knowing that this data has been published to Server A.
- Client A receives this new data because it is connected to Server A.
- Client B never receives this new data despite being subscribed to Room C because it is connected to Server B.
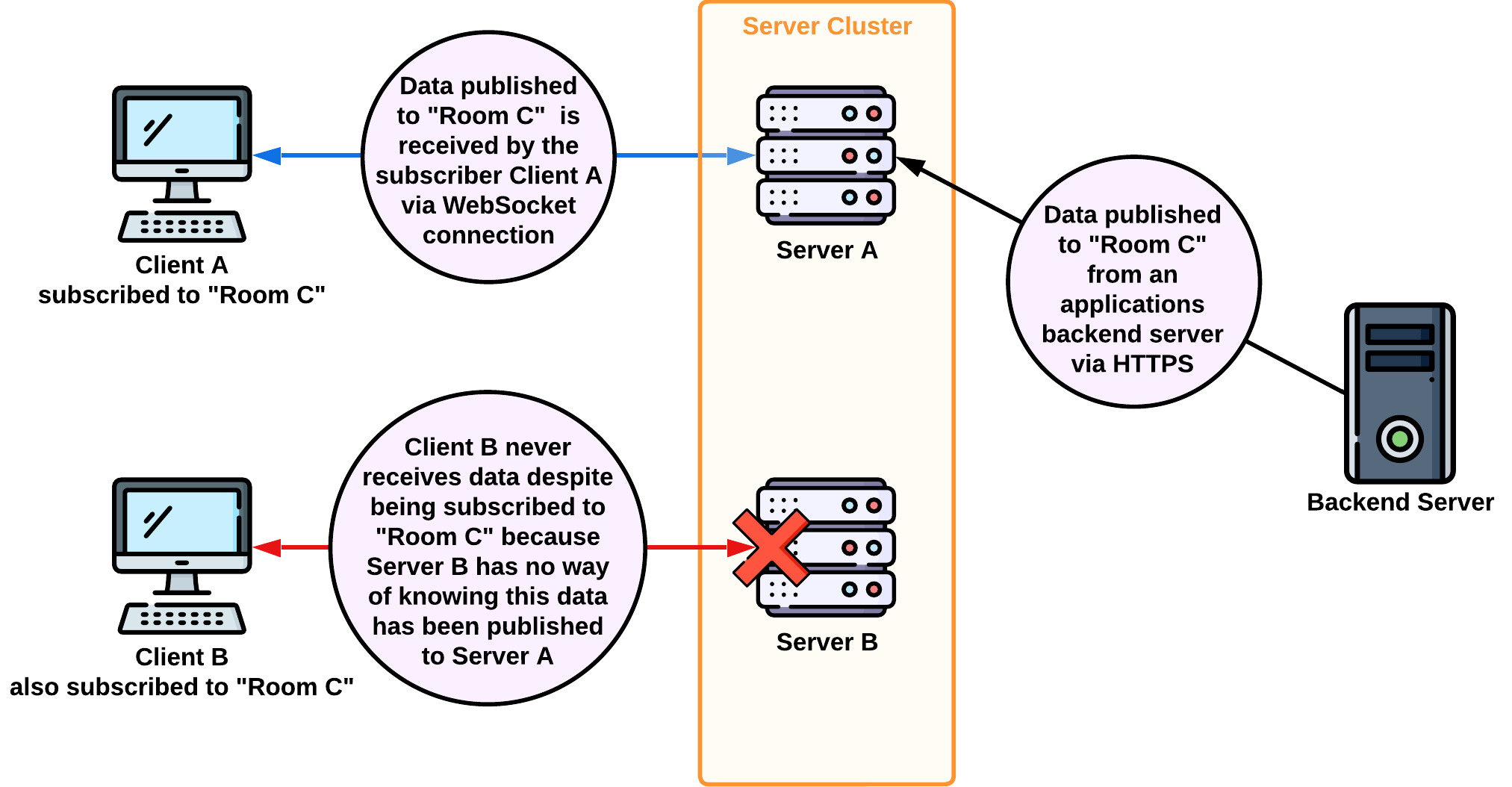
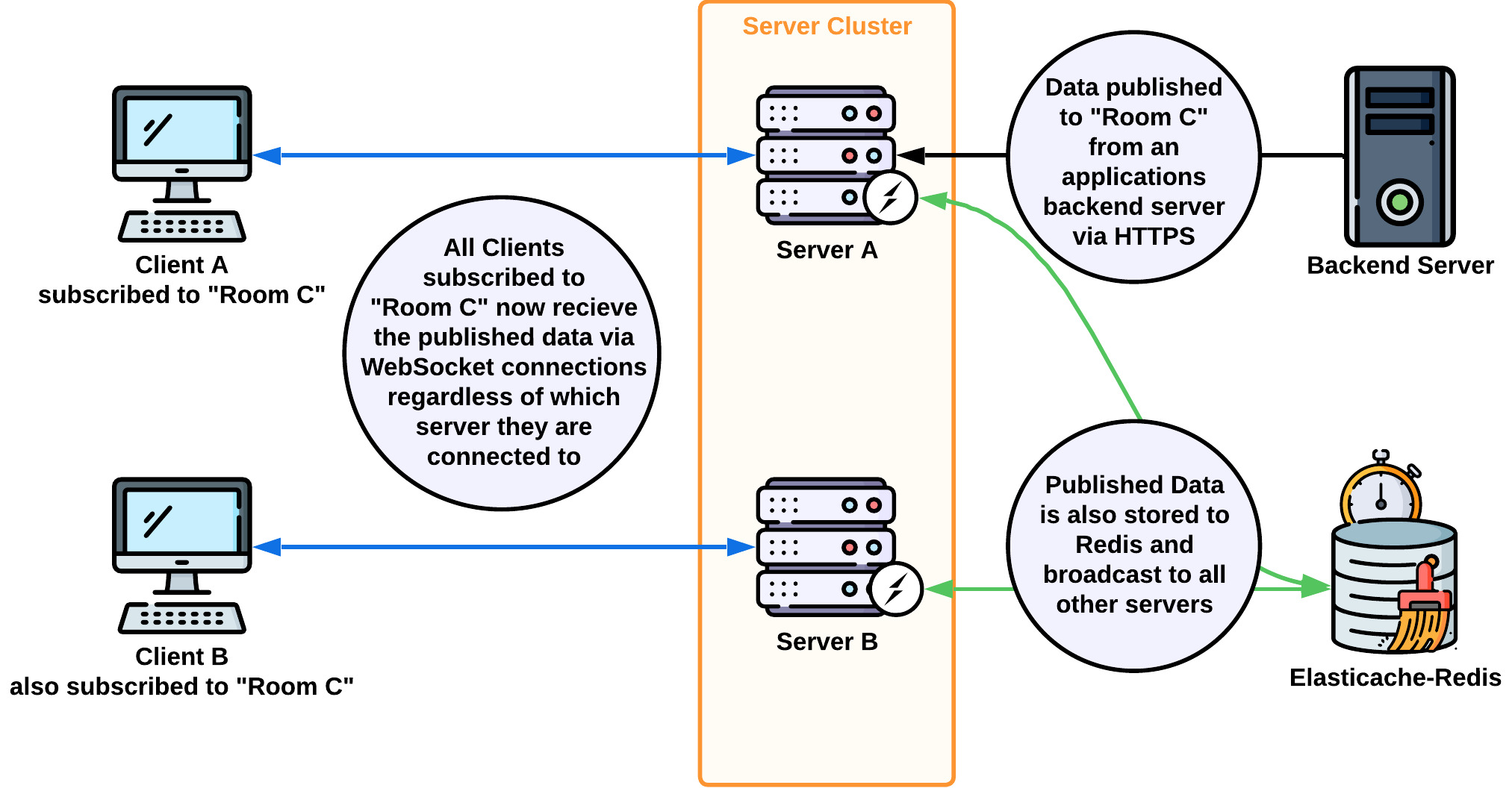
To solve this issue, we implemented the Socket.Io Redis adapter. Now, when data is received by one Twine server instance, it is also published by that instance to Redis using the socket.io-redis adapter logic. Redis, in turn, broadcasts that data to all Twine servers so they can access it. It's important to note that this functionality of Redis is separate from our use of Redis for connection state recovery logic discussed in section 8.3.
7.3.0 Load Testing Twine
Twine chose Artillery for load testing because of its built-in Socket.IO engine, which enabled a straightforward connection to the Twine server. However, in Artillery, "each virtual user will pick and run one of the scenarios - the set of steps taken - in the test definition and run it to completion."1 That made Twine difficult to simulate in Artillery because the user flow requires a successful /set-cookie request followed by a second request that establishes the WebSocket connection, and we wanted to add custom error reporting.
These issues were addressed by adding custom processing for Artillery load tests: extracting the Artillery "scenario" logic from the limited YAML options to a more complex JavaScript file. With that in place, each of Artillery's virtual users fetched a cookie, established a WebSocket connection with the Twine server, and maintained that connection, all in sequence. Custom error reporting tracked the success or failure of each virtual user's /set-cookie request, WebSocket connection interactions, and when applicable, the receipt of a payload published over the WebSocket connection.
Load testing Twine with 96,000 concurrent virtual users placed too much strain on the AWS EC2 instance running Artillery: maintaining tens of thousands of WebSocket connections created with the Socket.IO client library quickly reached the server's memory limit. We also found that the Artillery server had a limited number of ephemeral ports and open file descriptors, and each WebSocket connection required one of each. To resolve these issues, we increased the CPU, memory, and network performance of the EC2 instance and added another, to load test Twine with both concurrently.
Phase one load tested a Twine deployment by ramping up to 96,000 concurrent virtual users over 20 minutes: the Twine servers auto-scaled from 1 to 4 based on a CPU threshold and breach duration trigger (how long the threshold must be crossed), and handled the load successfully.
Phase two load tested ramping up to 40,800 virtual users over 20 minutes, and added the strain of subscribing each virtual user to one room and emitting 1 message per second to all users in that room. The Twine architecture handled the load without issue. However, the test report showed that 20-40% of virtual users, spread across the load test duration, connected yet failed to receive a single message. A load test of 6,000 virtual users over 10 minutes reported the same result. At the same time, Twine server metrics showed low CPU and memory usage.
The failure rate immediately dropped to 2-4% when we upgraded the Artillery servers and ran multiple 6,000-virtual-user load tests, but it increased when testing with more concurrent connections. Following these results, we ran a simplified Artillery test that ramped up to 48,000 concurrent connections over 20 minutes: message receipt errors occurred for 0.7% of virtual users. While the results were encouraging, the test configuration did not combine the /set-cookie and WebSocket requests into a single flow for each virtual user.
After examining server metrics and Artillery reports, we believe the errors were caused by an Artillery server bottleneck, the load test configuration, or a combination thereof. We are investigating further and also working on configuring Artillery to load test connection state recovery specific to each virtual user.
8.0 How to Use Twine
To use Twine in their existing application, a developer must:
- Deploy their Twine real-time service using AWS CLI and CloudFormation.
- Import the Twine Client library to their front-end code, which allows clients to interact with the Twine service.
- Import the Twine Server library to their back-end code, which enables the publishing of data to the Twine service.
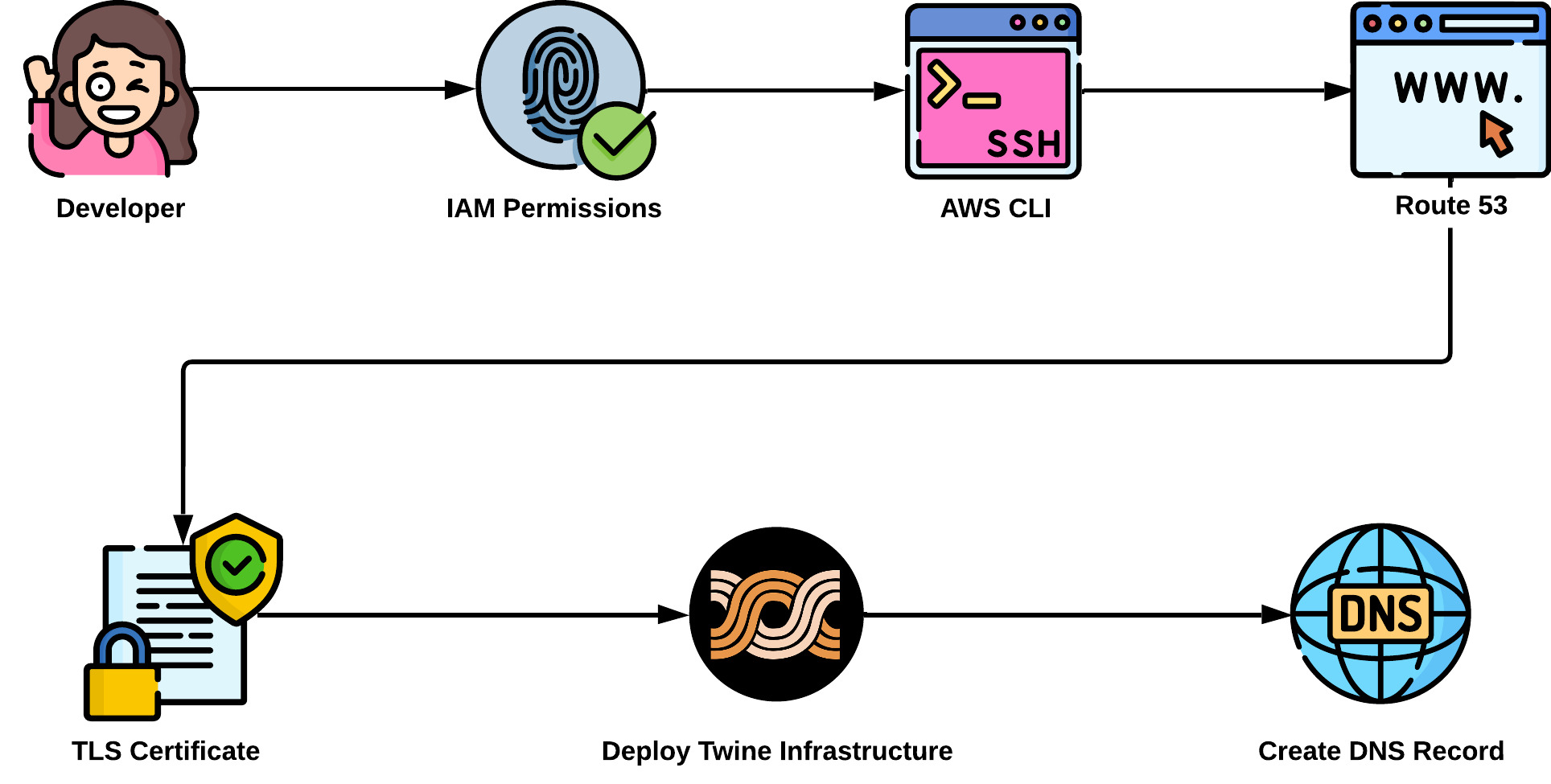
8.1.0 CLI and CloudFormation
Following the detailed steps laid out in the Twine Deployment document, to deploy their real-time service, a developer needs to take the following steps:
- Create an AWS account and IAM User to configure all necessary permissions
- Create an AWS CLI profile that will later be used to deploy Twine
- Register a Route 53 domain that will later be used with the Twine libraries
- Request a TLS Certificate
- Deploy the Twine Architecture
- Create a DNS Record to ensure the load balancer routes users appropriately
Once these steps have been followed, the Twine infrastructure will be complete and ready to connect to via the Twine client and server libraries.
This approach keeps a developer's sensitive information like their AWS access and secret keys private. Twine will only need to know the public domain created by the developer during Route 53 registration.
8.2.0 Client-Side Library
In this two-step process, the developer must first import the Twine Client Library from the jsDelivr CDN by adding the following line of code into their JavaScript code:
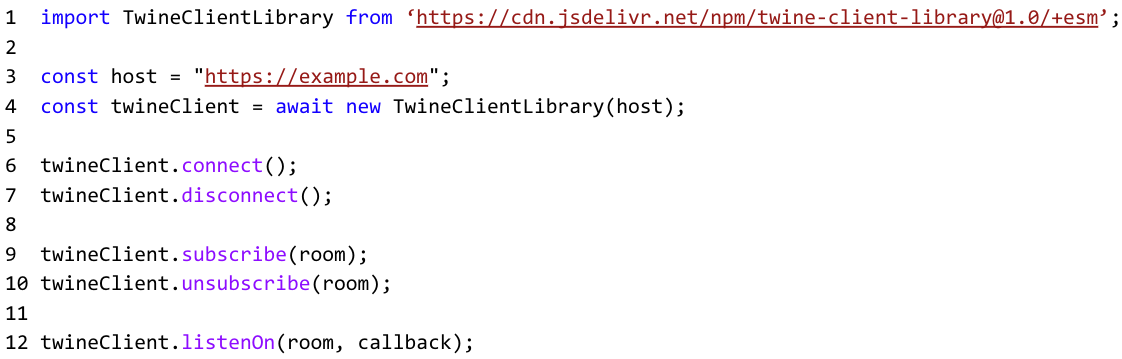
Next, the developer needs to configure the client using the Twine constructor and their newly created Twine domain name.
Once the constructor is invoked, a TwineClientLibrary instance is created and a connection is established with the Twine server. From here, the developer has access to built-in functions they can use to connect/disconnect the WebSocket connection manually; subscribe/unsubscribe users to a particular room; and listen for messages being sent to a particular room - passing in a callback function to handle the data as they see fit coming from the backend.
8.3.0 Server-Side Library
In this two-step process, the developer must first import the Twine Server Library from the jsDelivr CDN by adding the following line of code into their JavaScript code:

Next, the developer needs to configure the client using the Twine constructor and their newly created Twine domain name.
Once the constructor is invoked, messages may be published to the Twine server using the built-in publish method.
9.0 Future Work
While we are happy with Twine, the following are some improvements we would like to make in the future.
9.1.0 Separating HTTP from WebSocket traffic on our server via a backchannel
In our current architecture, our servers are being used for both WebSocket connections and HTTP traffic in the form of messages being published from the developer's backend.
The issue is that WebSocket and HTTP protocols differ in a fundamental way that changes scaling parameters. This inconsistency can lead to increased resource usage and latency, which can diminish the performance of the application as it scales.
Ideally, we would like to build a gateway specifically for HTTP traffic. Separating these two types into their own server farms would ensure our servers are scaling with consistent parameters.
9.2.0 In-transit Data Processing
As mentioned in our introduction, the WebSocket protocol enables bi-directional data transfer from both server to client and client to server over a single long-lived connection. In our current architecture, business logic used to process any incoming data from clients would need to be implemented by the developer using Twine. Examples of processing a developer may want to perform on client data include:
- routing data to a third party
- filtering data for profanity
- manipulating data, e.g. text to speech
Currently, the developer would need to first route client data to their application's backend server for processing and then to Twine to publish. In addition, the developer would then be concerned with their own server's scalability as their app grows and the number of incoming data increases.
We would like to add an in-transit data processing feature, such as serverless functions, to Twine that would allow the developer to dynamically process incoming data from clients. The added logic will improve their user experience while removing the added complexity and load from their backend server.
10.0 References
Thank you for reading. We hope you enjoy using Twine!
- How Fast is Realtime? Human Perception and Technology
- The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information
- Server-sent events
- Upgrade - HTTP | MDN
- WebSockets vs HTTP
- What Are WebSockets Used For?
- WebSockets Pros & Cons
- HTTP vs WebSockets: A Performance Comparison
- WebSockets Guide
- Software Scalability
- How to Scale Your Software Product
- TechTerms - Scalable
- Horizontal vs Vertical Scaling
- The Challenge of Scaling WebSockets
- WebSocket Performance Checklist
- QuickNode Support - WebSocket Guide
- Socket.IO Connection State Recovery
- WebSockets - Memory Management
- G-Core Labs
- Pusher vs PubNub vs Firebase
- Ably vs Pusher Comparison
- Ably Documentation - Limits
- Ably Privacy Policy
- Amazon Web Services (AWS) - Wikipedia
- Web Scalability for Startup Engineers, By Artur Ejsmont
- Ably FAQs - Connection State Recovery
- At Most Once, At Least Once, Exactly Once Semantics
- Achieving Exactly Once Message Processing with Ably
- AWS Elastic Beanstalk Documentation
- Pub-Sub Messaging Pattern
- LocalStorage vs Cookies
- Socket.IO Protocol - Upgrade Mechanism
- How Socket.IO Works - Upgrade Mechanism
- Using Multiple Nodes
- AWS Sticky Sessions Documentation
- Socket.IO Redis Adapter
- What Are WebSockets Used For?